💡 ElcamyではGoogle Cloudを用いたデータ分析基盤の構築や、生成AIを用いた業務支援まで対応可能です。生成AIやデータ活用によって事業を前に進めたい方は、お気軽にご相談ください。
1. 序論
データマイニングの定義と重要性
データマイニングは、大量のデータセットから有用な情報やパターンを抽出するプロセスです。これには、データの収集、前処理、解析、評価が含まれ、さまざまなアルゴリズムと技法が用いられます。データマイニングは、ビジネス、科学、医療、政府など多岐にわたる分野で利用され、意思決定、予測、パフォーマンスの向上に貢献します。
データマイニングの全体像
-
Data Collection: データの収集
-
Data Preprocessing: データの前処理
-
Data Transformation: データの変換
-
Data Mining: データマイニング
-
Pattern Evaluation: パターンの評価
-
Knowledge Representation: 知識の表現
-
Decision Making: 意思決定
データマイニングの歴史と発展
データマイニングは、統計学や機械学習の発展とともに進化してきました。1980年代にはデータベース管理システムの普及により、大量のデータが蓄積され始めました。1990年代には、データウェアハウスとOLAP(オンライン分析処理)技術の進展により、企業が蓄積したデータを活用しやすくなりました。21世紀に入り、ビッグデータやクラウドコンピューティングの台頭により、データマイニングはますます重要な役割を果たしています。
データマイニングの歴史を示すタイムライン

-
1980s: 初期の概念と技術の確立
-
1989: データベースにおける知識発見(KDD)という用語が生まれる
-
1990s: 機械学習アルゴリズムの開発
-
1996: 最初のKDDカンファレンス開催
-
2000s: データウェアハウジングとデータマイニング技術の進展
-
2010: ビッグデータ時代の到来
-
2012: ディープラーニングの革命
-
2015: AIとデータマイニングの統合
-
2020: 自動機械学習(AutoML)の普及
-
2023: リアルタイムデータマイニングとAIの進展
2. データマイニングのプロセス
データ収集
データマイニングの最初のステップは、データの収集です。これは、内部データベース、ウェブスクレイピング、センサーデータ、ソーシャルメディアデータなど、さまざまなソースからデータを収集することを含みます。データの質と量は、分析結果の精度と有用性に直接影響します。
データ準備(前処理)
収集したデータは、そのままでは分析に適していない場合が多いため、前処理が必要です。データクリーニング、データ統合、データ変換、データ削減などのステップを経て、データを分析に適した形式に整えます。
「データ収集」〜「データ準備の各ステップ」を示すフローチャート
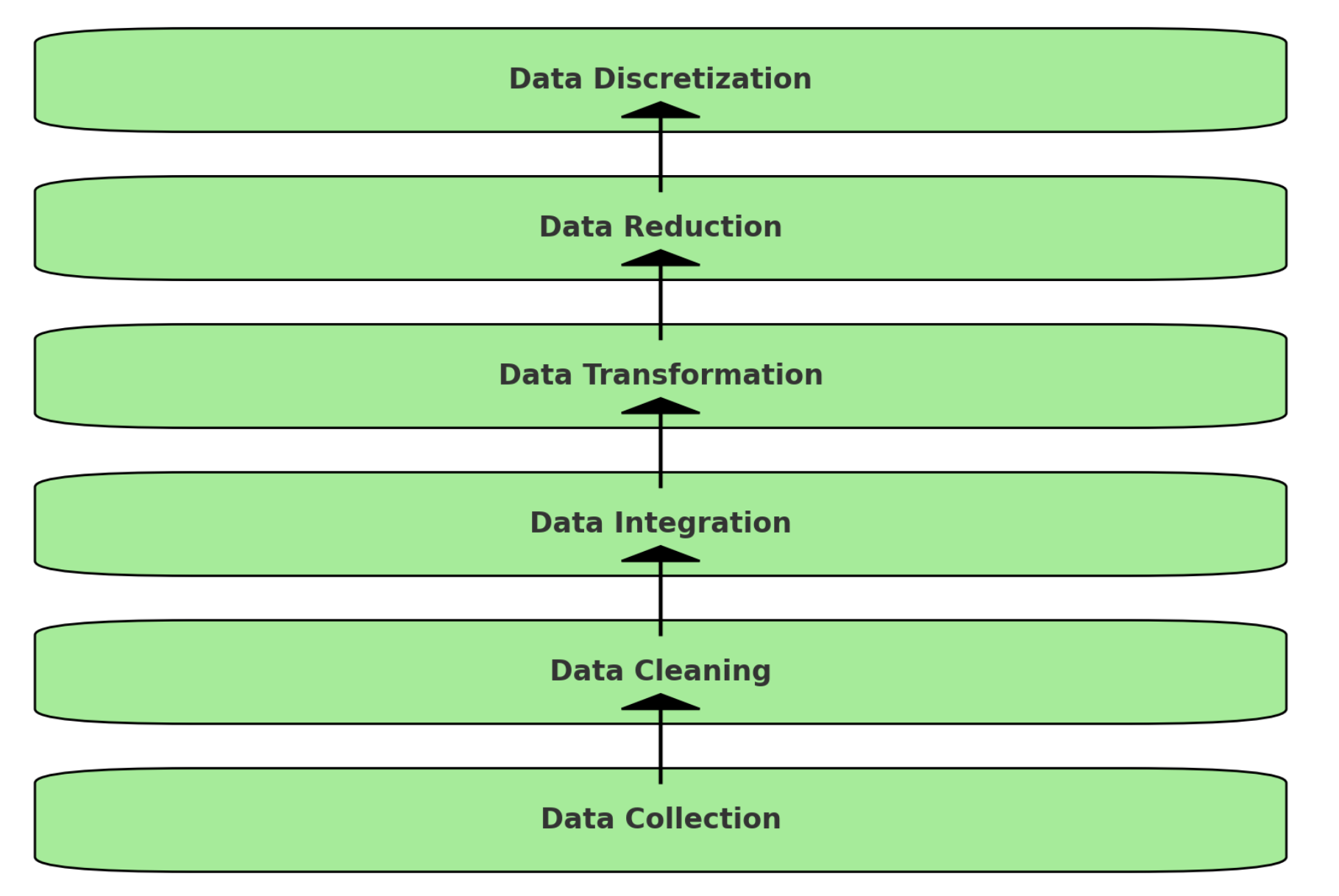
-
Data Collection: データの収集
-
Data Cleaning: データのクレンジング(欠損値や異常値の処理)
-
Data Integration: データの統合(異なるソースからのデータをまとめる)
-
Data Transformation: データの変換(正規化や標準化など)
-
Data Reduction: データの縮小(次元削減やサンプルの減少)
-
Data Discretization: データの離散化(連続データをカテゴリデータに変換)
データ探索
前処理が完了したデータは、探索的データ解析(EDA)を通じて、基本的な統計量の計算や可視化を行います。これにより、データの特徴を理解し、潜在的なパターンや異常を発見します。
モデリング
データ探索の結果を基に、適切なデータマイニングアルゴリズムを選択し、モデルを構築します。モデルの構築には、クラスタリング、分類、回帰分析、アソシエーションルール、異常検知などの技法が使用されます。
評価と解釈
構築したモデルの精度と有用性を評価します。モデルの評価には、交差検証、混同行列、精度、再現率、F1スコアなどの指標が用いられます。評価結果を基にモデルを改善し、最終的な解釈を行います。
デプロイメント(実装)
評価と解釈が完了したモデルは、実際の業務やシステムに組み込みます。これにより、モデルの予測や分析結果を日常業務に活用し、意思決定やパフォーマンスの向上を図ります。
データマイニングプロセスの全体フローチャート(データ収集から実装までの各ステップ)
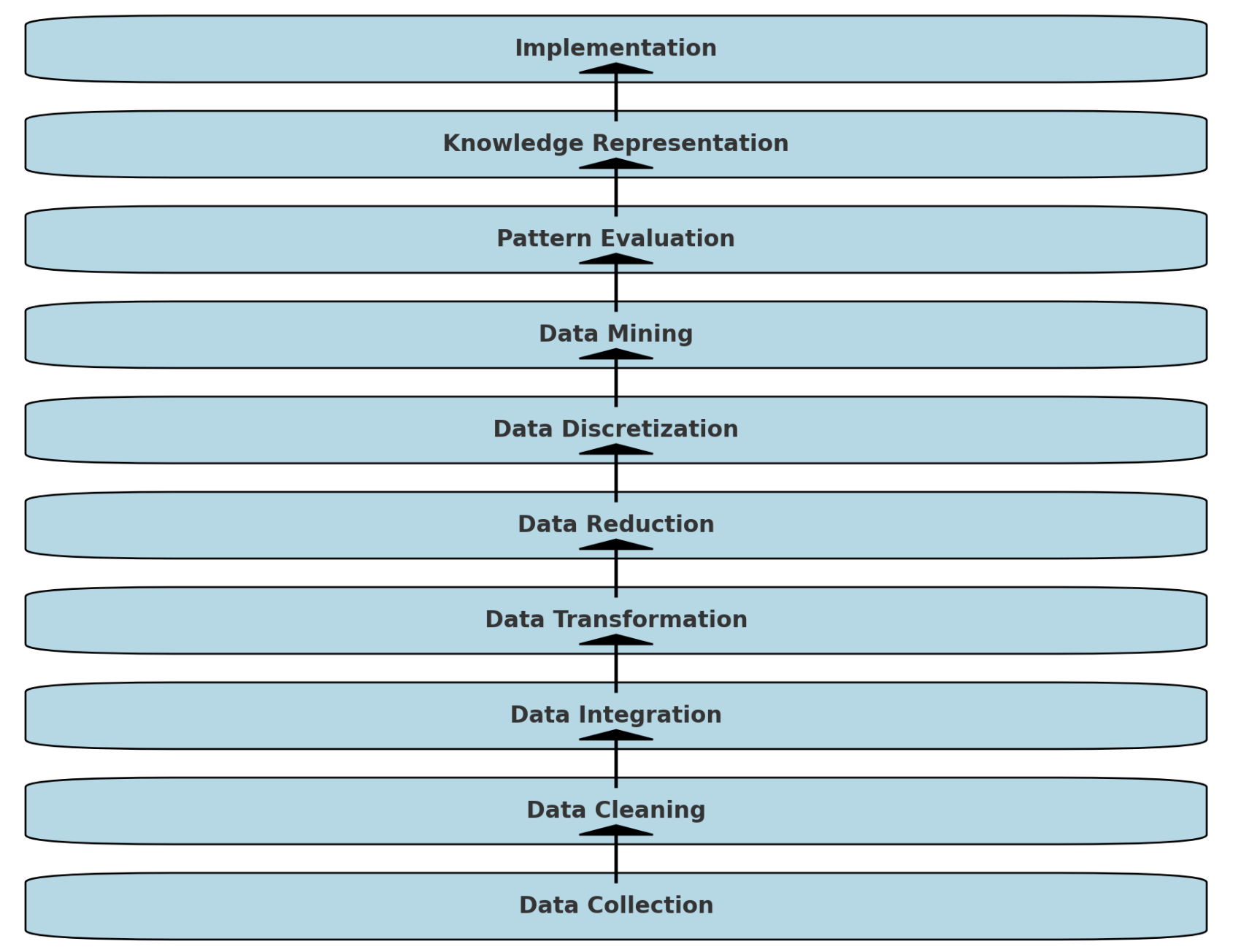
-
Data Collection: データの収集
-
Data Cleaning: データのクレンジング(欠損値や異常値の処理)
-
Data Integration: データの統合(異なるソースからのデータをまとめる)
-
Data Transformation: データの変換(正規化や標準化など)
-
Data Reduction: データの縮小(次元削減やサンプルの減少)
-
Data Discretization: データの離散化(連続データをカテゴリデータに変換)
-
Data Mining: データマイニング(パターンやモデルの発見)
-
Pattern Evaluation: パターンの評価(発見されたパターンの有用性評価)
-
Knowledge Representation: 知識の表現(発見された知識の視覚化や報告)
-
Implementation: 実装(発見された知識を実際のビジネスプロセスに適用)
3. データマイニングの技法とアルゴリズム
データマイニングにはさまざまな技法とアルゴリズムが用いられます。以下では、主要な技法とそのアルゴリズムについて説明します。
クラスタリング
クラスタリングは、データセットを類似したデータポイントのグループ(クラスタ)に分割する技法です。この技法は、データの構造を理解し、自然に形成されたグループを発見するために用いられます。
代表的なアルゴリズム
- K-means:データポイントを事前に指定したK個のクラスタに分割します。各クラスタは、その重心(セントロイド)によって定義されます。
- 階層型クラスタリング:データポイントを階層的に分割し、樹形図(デンドログラム)として表示します。階層型クラスタリングは、クラスタの数を事前に指定する必要がありません。
K-meansクラスタリングの例を示す図(データポイントが色分けされたクラスタに分割される様子)
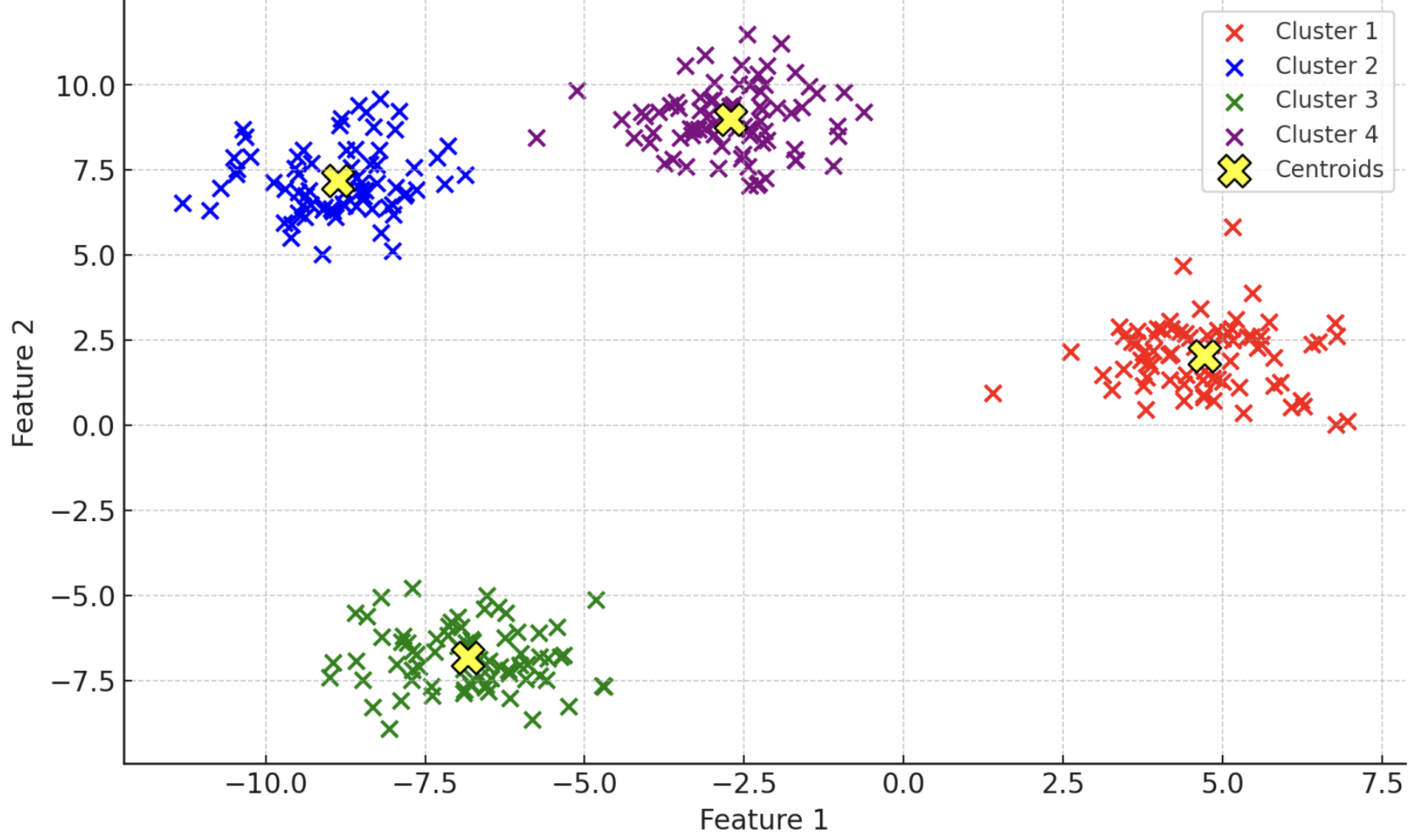
データポイントが色分けされ、それぞれのクラスタに分割されています。
黄色のXマークは各クラスタの中心点(セントロイド)を示しています。
• 赤: クラスタ1
• 青: クラスタ2
• 緑: クラスタ3
• 紫: クラスタ4
この図は、K-meansアルゴリズムがデータポイントをどのようにクラスタに分類するかを視覚的に示しています。
分類
分類は、データポイントを事前に定義されたカテゴリ(クラス)に割り当てる技法です。これは、スパムメールの検出、顧客の購買行動予測、病気の診断などに広く利用されています。
代表的なアルゴリズム
- 決定木:データポイントを特徴量に基づいて分割し、木構造として表示します。各葉はクラスラベルを持ちます。
- ランダムフォレスト:複数の決定木を組み合わせて予測を行います。個々の決定木の予測結果を集約し、最終的なクラスを決定します。
- サポートベクターマシン(SVM):データポイントを高次元空間にマッピングし、最大のマージンを持つ分離超平面を見つけます。
決定木の例を示す図(特徴量に基づいたデータポイントの分割とクラスラベルの割り当て)
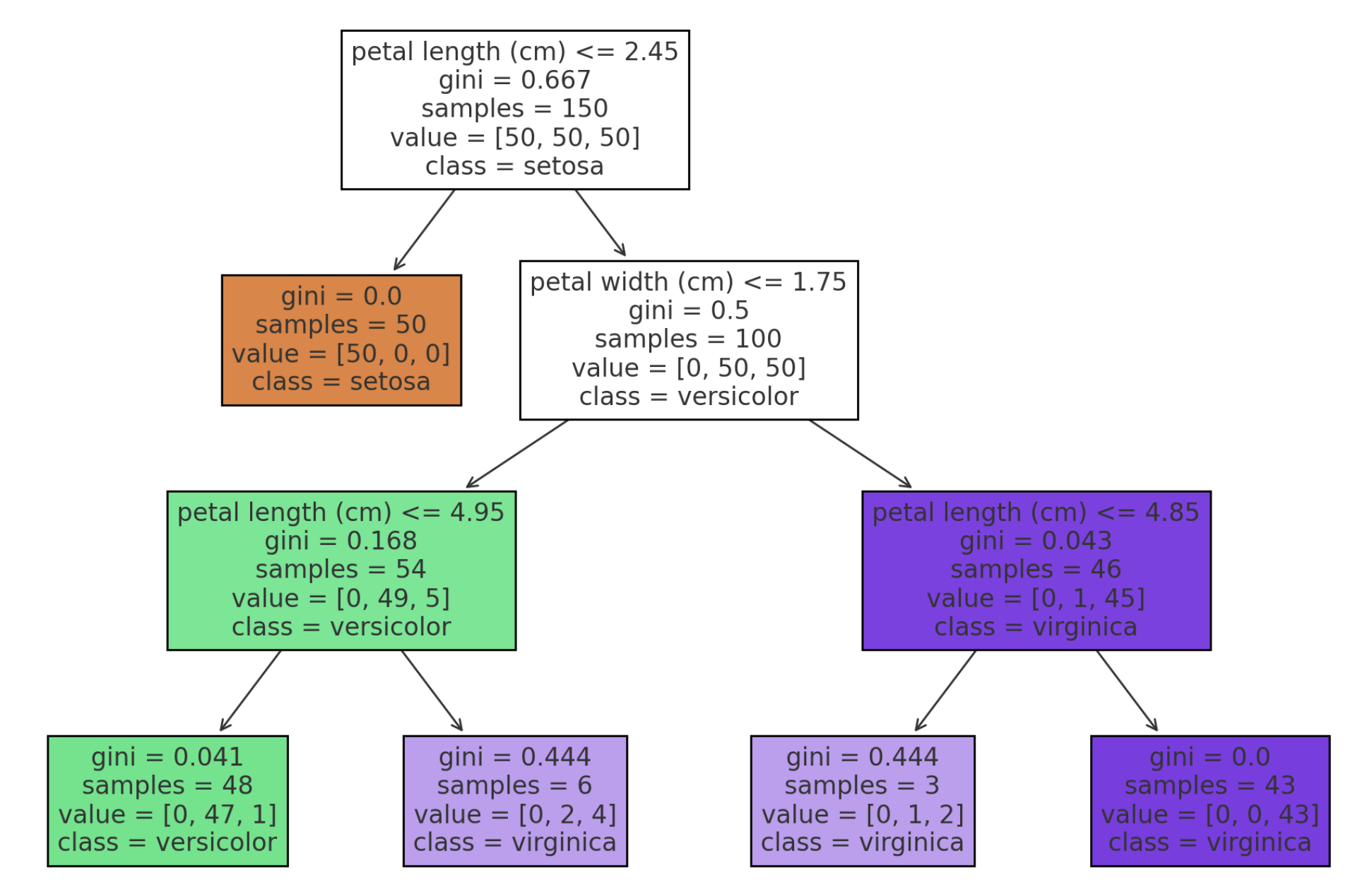
特徴量に基づいてデータポイントを分割し、クラスラベルを割り当てるプロセスを視覚的に示しています。
• ノード: 各ノードはデータポイントの分割条件を表し、特徴量としきい値が記載されています。
• 枝: 各枝はノードの分割結果を示し、データポイントが次のノードにどのように進むかを示します。
• 葉ノード: 最終的なクラスラベルが割り当てられるノードで、クラスの分布が示されています。
この決定木は、アイリスデータセットを使用しており、特徴量(花弁や萼片の長さと幅)に基づいて3つの異なるアイリスの種類を分類しています。
回帰分析
回帰分析は、連続値を持つターゲット変数を予測する技法です。これは、売上予測、住宅価格の推定、気温予測などに利用されます。
代表的なアルゴリズム
- 線形回帰:ターゲット変数と特徴量との線形関係をモデル化します。単純なモデルで解釈しやすいのが特徴です。
- ロジスティック回帰:分類問題に用いられ、ターゲット変数が二値(0または1)の場合に適用されます。確率的な結果を提供します。
線形回帰の例を示す図(データポイントと回帰直線の関係)
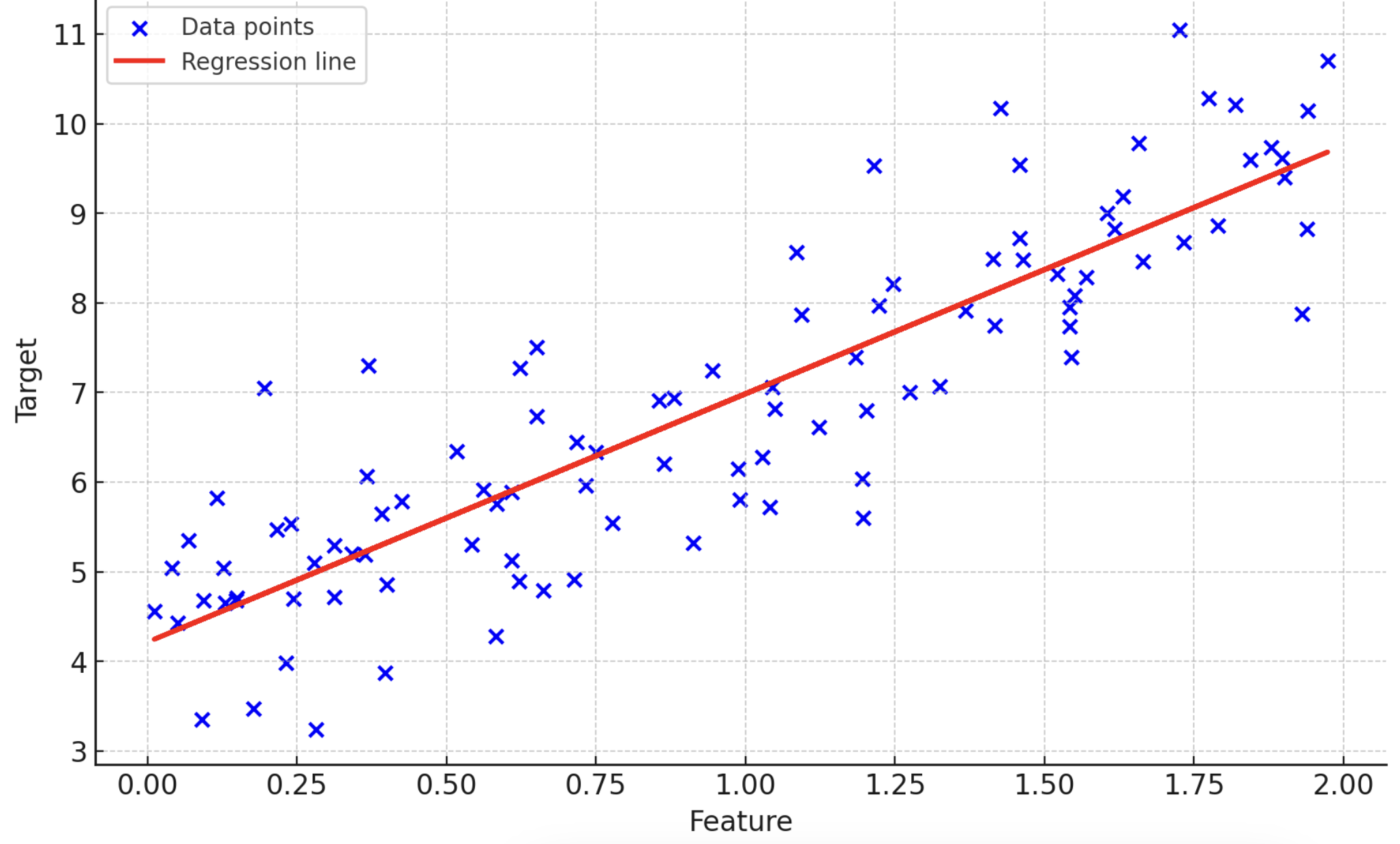
青い点がデータポイントを表し、赤い線が回帰直線を示しています。
• データポイント: 観測されたデータ(特徴量とターゲットのペア)
• 回帰直線: 線形回帰モデルによって予測された関係を示す直線
この図は、特徴量(独立変数)とターゲット(従属変数)の関係を視覚的に示し、線形回帰がどのようにデータポイントを近似するかを表しています。
アソシエーションルール
アソシエーションルールは、データセット内のアイテム間の関連性を発見する技法です。これは、マーケットバスケット分析(例えば、顧客が一緒に購入する商品を特定する)に利用されます。
代表的なアルゴリズム
- Apriori:頻繁に一緒に現れるアイテムセットを見つけ、それに基づいてアソシエーションルールを生成します。
- FP-Growth:頻繁パターンツリーを構築し、効率的に頻繁アイテムセットを見つけます。
アソシエーションルールの例を示す図(マーケットバスケット分析の結果)
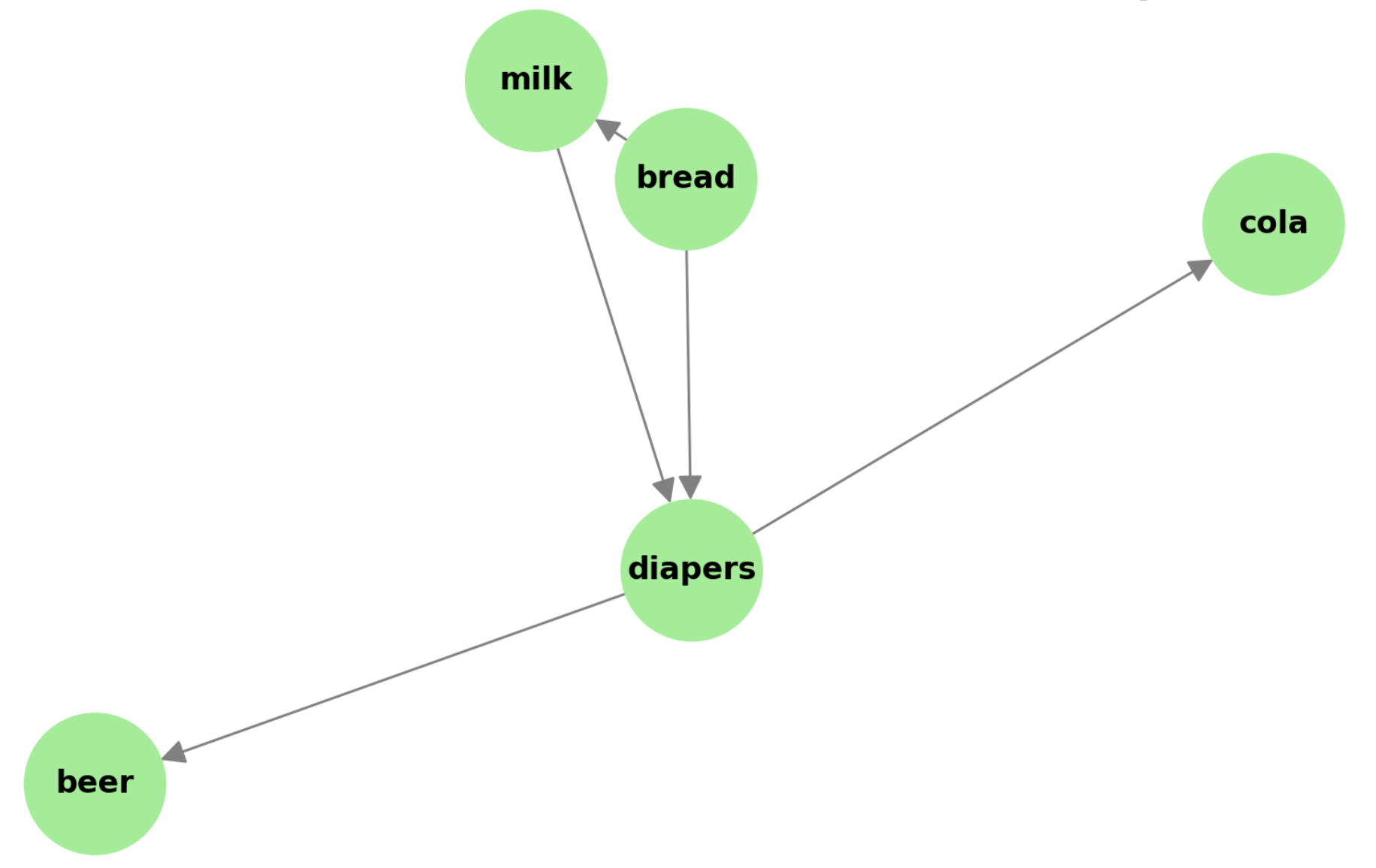
マーケットバスケット分析の結果、特定の商品が一緒に購入される傾向があることを示しています。
• ノード: 各商品(例:パン、ミルク、おむつ、ビール、コーラ)
• エッジ(矢印): 商品の間のアソシエーションルール(例:パンを購入する人はミルクも購入する傾向がある)
この図は、顧客がどのような組み合わせで商品を購入する傾向があるかを視覚的に示し、マーケティング戦略や店舗レイアウトの最適化に役立てることができます。
異常検知
異常検知は、データセット内の異常なデータポイント(異常値)を特定する技法です。これは、不正検出、ネットワーク侵入検知、機械の故障予知などに利用されます。
代表的なアルゴリズム
- Isolation Forest:データポイントをランダムに分割し、異常なポイントが孤立するまでのプロセスを観察します。
- K-nearest neighbors (KNN):データポイントの近傍を調べ、周囲のポイントと大きく異なるポイントを異常として検出します。
異常検知の例を示す図(異常値が明確に特定される様子)
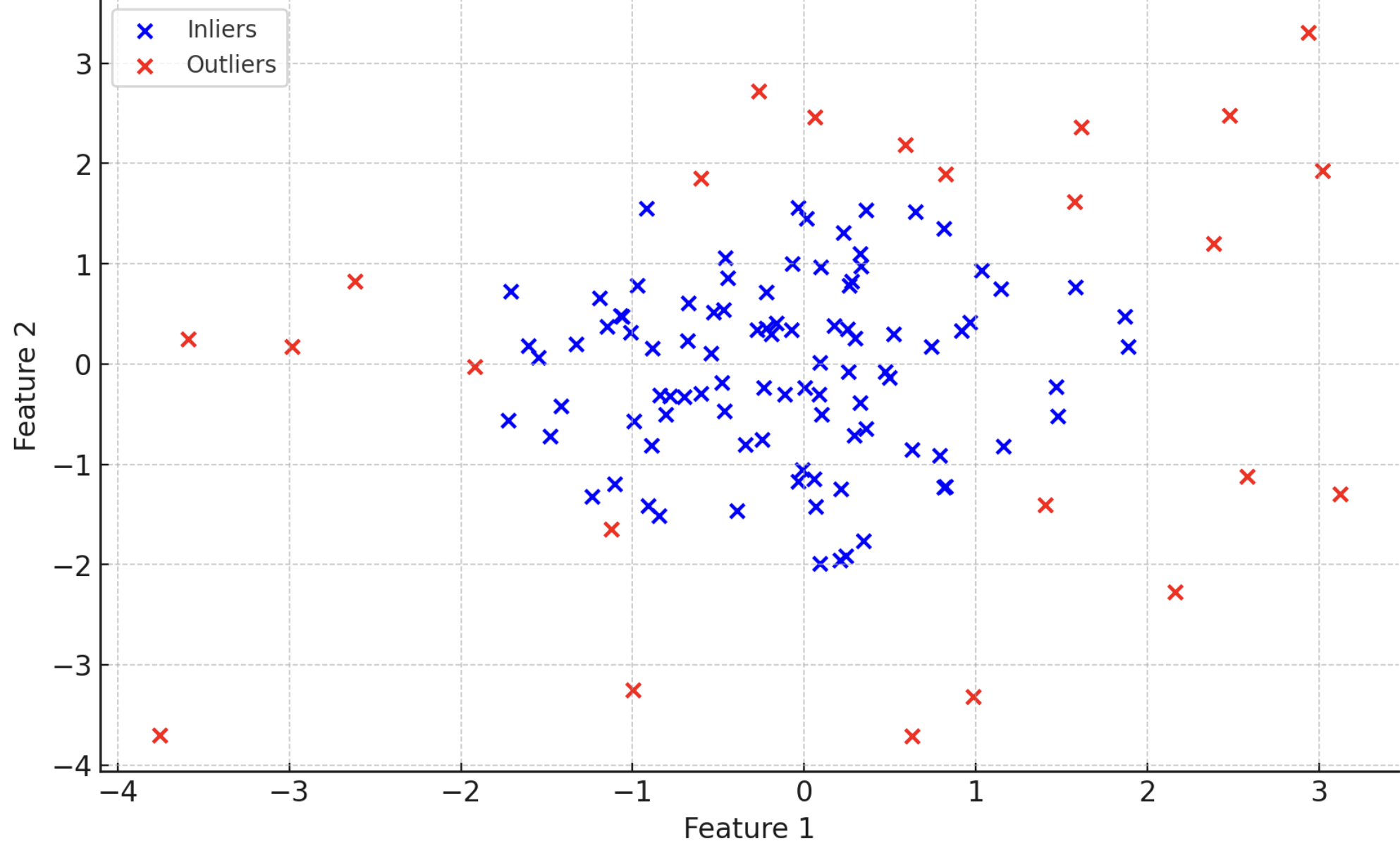
異常値(赤い点)が正常なデータポイント(青い点)から明確に特定されています。
• 青い点: 正常なデータポイント(Inliers)
• 赤い点: 異常値(Outliers)
この例では、Isolation Forestアルゴリズムを使用して異常値を検知しています。異常値は、正常なデータポイントから大きく外れた位置にあり、視覚的に特定することができます。
4. データマイニングの応用例
データマイニングは、多岐にわたる分野で活用され、さまざまなビジネスや科学的な問題の解決に貢献しています。以下にいくつかの具体的な応用例を示します。
4.1 マーケティングと顧客分析
データマイニングは、マーケティング戦略の最適化や顧客行動の理解に広く利用されています。
具体的な応用例
- 顧客セグメンテーション:顧客データを分析し、類似した購買行動や特性を持つ顧客グループを特定します。これにより、ターゲットを絞ったマーケティングキャンペーンが可能になります。
- クロスセルとアップセル:過去の購買データを基に、顧客が興味を持ちそうな商品やサービスを予測し、効果的なクロスセル(関連商品販売)やアップセル(上位商品販売)を実現します。
- 顧客離脱予測:顧客の行動データを分析し、離脱の兆候を早期に検出します。これにより、適切な対策を講じて顧客維持率を向上させます。
顧客セグメンテーションの結果を示すクラスタリング図
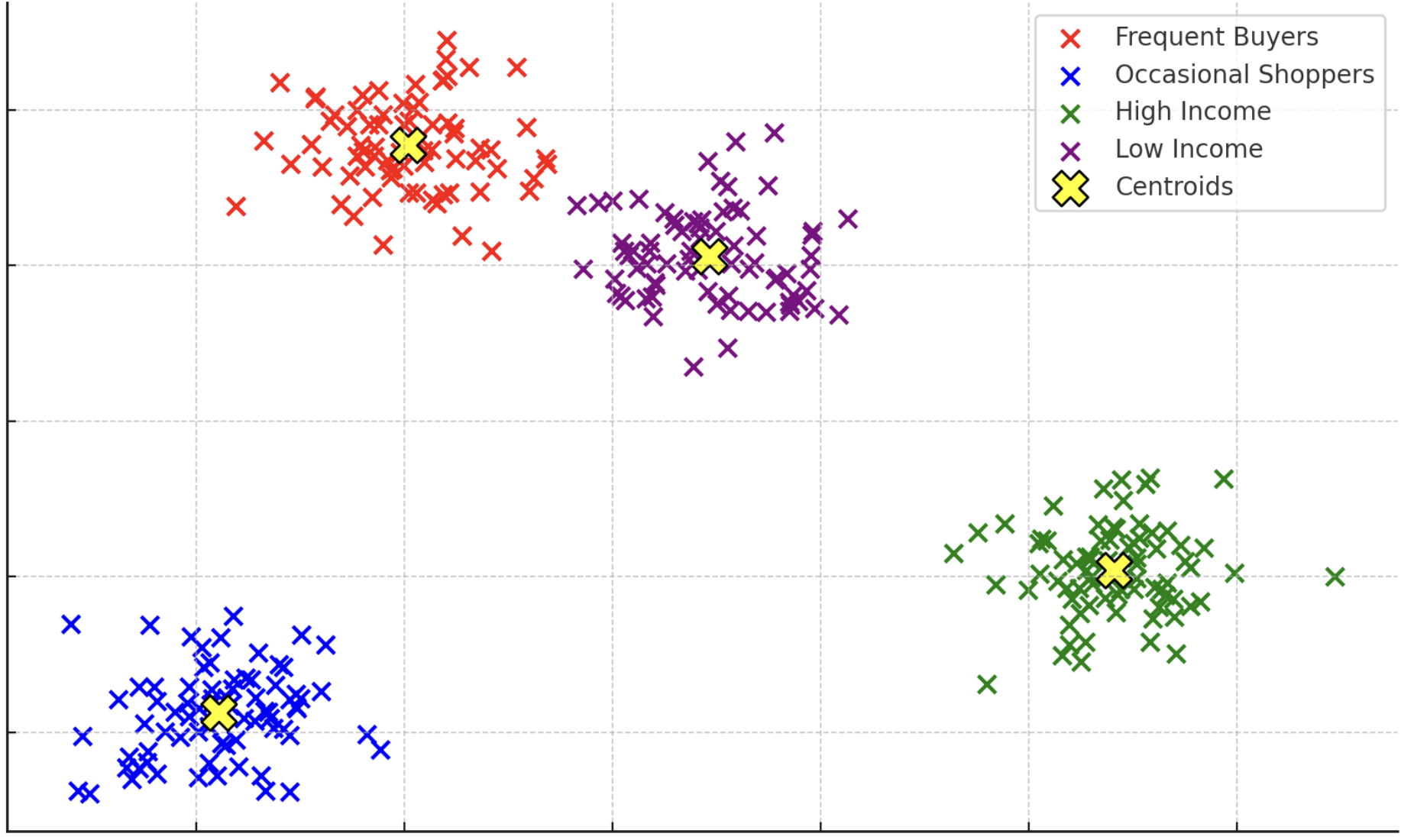
各セグメントは以下のようにラベル付けされています:
• 赤(Frequent Buyers): 頻繁に購入する顧客
• 青(Occasional Shoppers): 時折購入する顧客
• 緑(High Income): 高収入の顧客
• 紫(Low Income): 低収入の顧客
PCA(主成分分析)を使用して次元を減らした後のデータポイントを示しており、4つのセグメントに分割されています。各セグメントは顧客の特徴に基づいて分けられ、マーケティング戦略、特にクロスセル(関連商品を提案する)、アップセル(上位のサービスを提案する)、および顧客離脱予測(顧客が離れる前に対策を講じる)に役立てることができます。
4.2 金融とリスク管理
データマイニングは、金融業界でリスク管理や詐欺検出に役立っています。
具体的な応用例
- クレジットリスク評価:顧客の信用履歴や取引データを分析し、クレジットリスクを評価します。これにより、貸し倒れのリスクを低減できます。
- 詐欺検出:取引データをリアルタイムで監視し、異常なパターンを検出します。これにより、不正取引や詐欺行為を早期に発見できます。
- ポートフォリオ最適化:市場データを分析し、リスクとリターンのバランスを考慮した最適な投資ポートフォリオを構築します。
詐欺検出のフローチャート(取引データの監視と異常検出のプロセス)
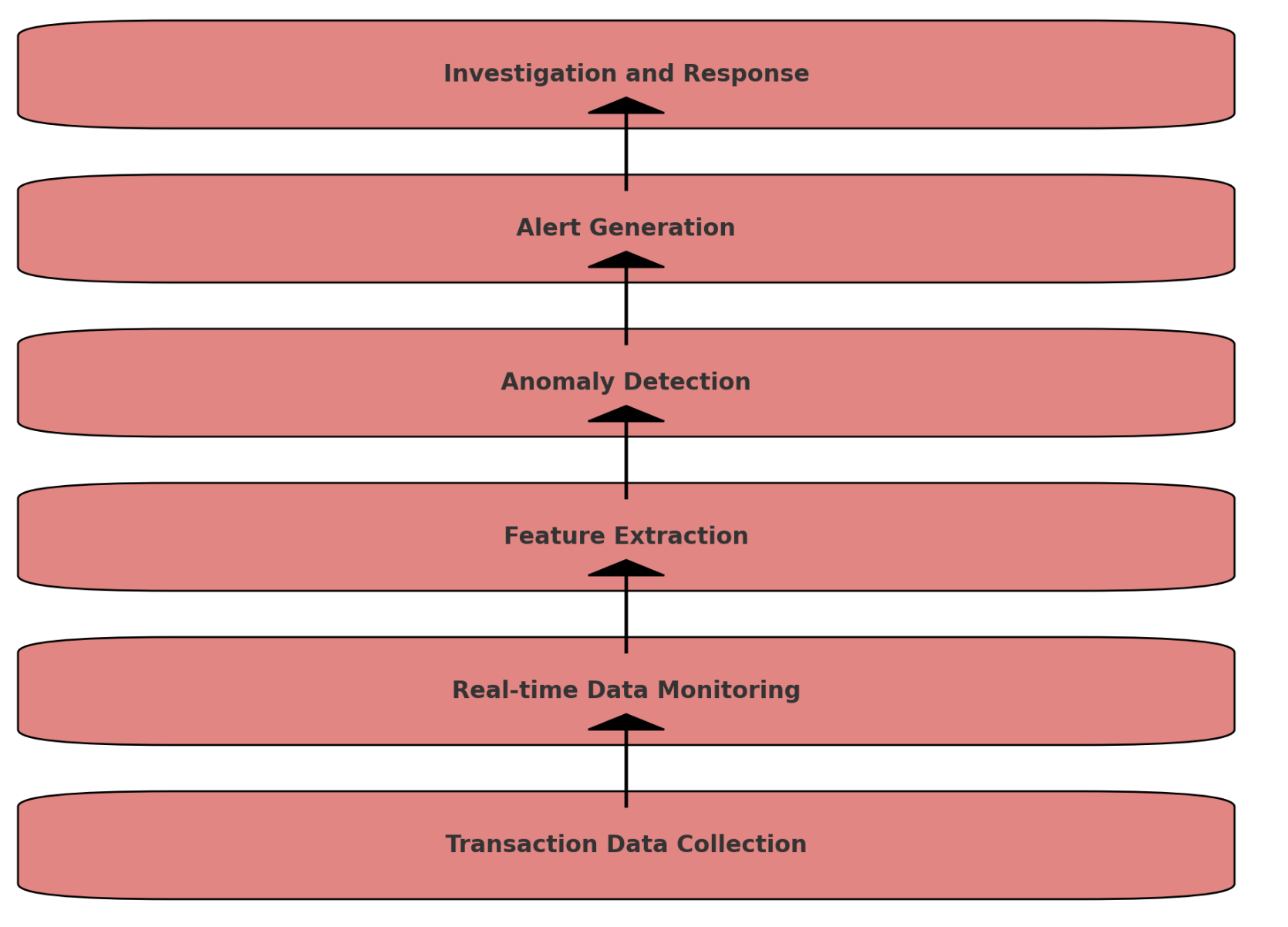
-
Transaction Data Collection: 取引データの収集
-
Real-time Data Monitoring: リアルタイムデータ監視
-
Feature Extraction: 特徴抽出
-
Anomaly Detection: 異常検出
-
Alert Generation: アラート生成
-
Investigation and Response: 調査と対応
4.3 ヘルスケアと医療診断
データマイニングは、ヘルスケア分野での診断精度向上や治療効果の最適化に利用されています。
具体的な応用例
- 病気の早期発見:患者データを分析し、病気の早期兆候を検出します。これにより、早期治療と予防が可能になります。
- 治療効果の予測:治療データを基に、特定の治療法がどの程度効果的かを予測します。これにより、個別化医療の実現が進みます。
- 患者セグメンテーション:患者データをクラスタリングし、類似した特性を持つ患者グループを特定します。これにより、グループごとに最適な治療プランを提供できます。
病気の早期発見におけるデータフロー図(患者データの収集から診断まで)
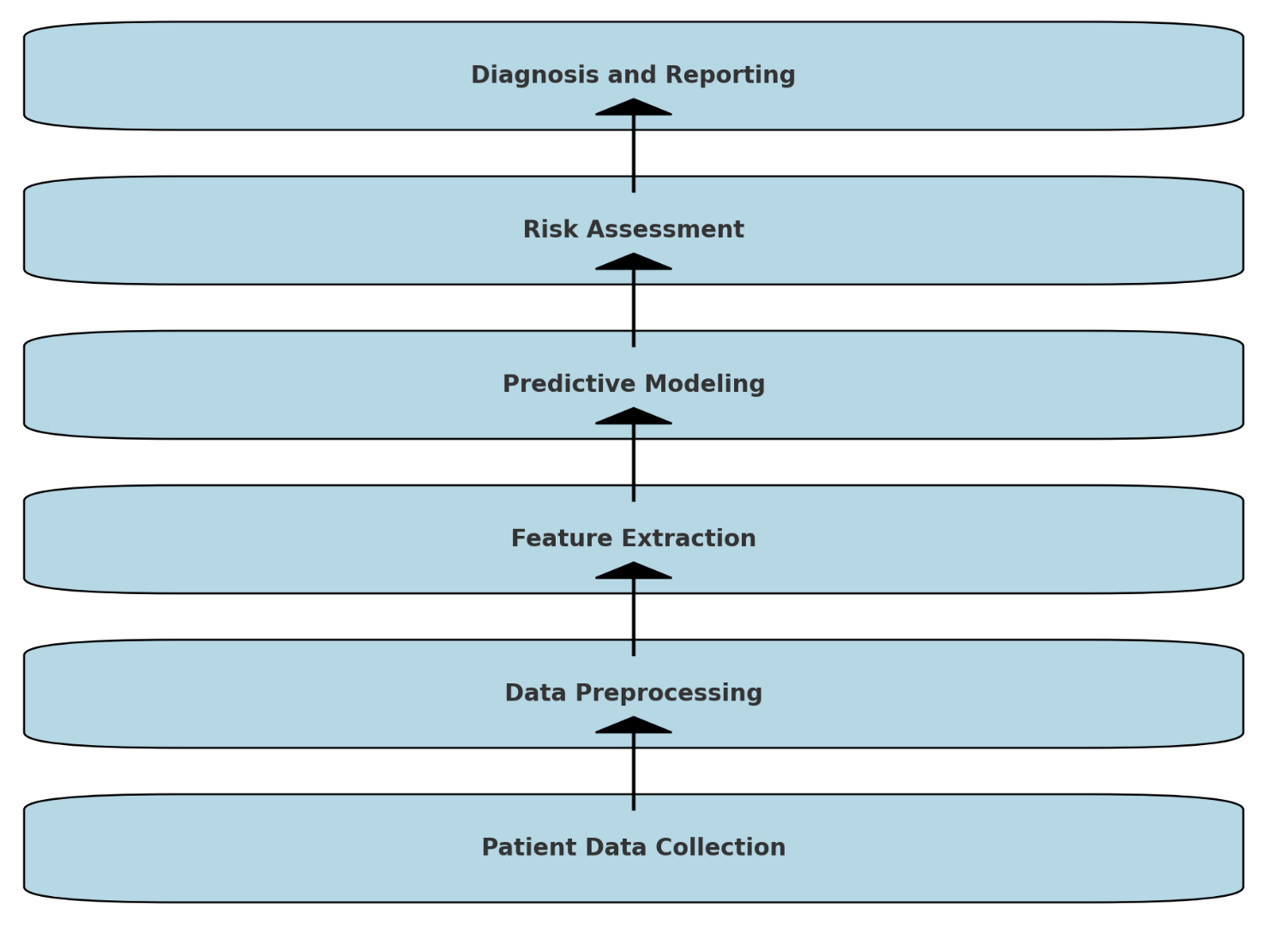
-
Patient Data Collection: 患者データの収集
-
Data Preprocessing: データの前処理
-
Feature Extraction: 特徴抽出
-
Predictive Modeling: 予測モデルの構築
-
Risk Assessment: リスク評価
-
Diagnosis and Reporting: 診断と報告
4.4 ソーシャルメディアと感情分析
データマイニングは、ソーシャルメディアデータの分析やユーザーの感情分析に利用されています。
具体的な応用例
- 感情分析:ソーシャルメディアの投稿やレビューを分析し、ユーザーの感情(ポジティブ、ネガティブ、中立)を判別します。これにより、製品やサービスに対するフィードバックをリアルタイムで把握できます。
- トレンド分析:大量の投稿データを分析し、現在のトレンドやホットトピックを特定します。これにより、マーケティング戦略の立案に役立てます。
- インフルエンサー分析:ソーシャルメディア上で影響力のあるユーザー(インフルエンサー)を特定し、プロモーション活動に活用します。
感情分析の結果を示す棒グラフや円グラフ
4.5 製造業と予知保全
データマイニングは、製造業における機器の故障予知や生産効率の向上に役立っています。
具体的な応用例
- 予知保全:機器のセンサーデータを分析し、故障の兆候を早期に検出します。これにより、計画的なメンテナンスを行い、ダウンタイムを最小限に抑えます。
- 品質管理:生産データをリアルタイムで監視し、品質に問題が発生した場合に即座に対応します。これにより、不良品の発生を減らし、製品の品質を向上させます。
- 生産最適化:生産ラインのデータを分析し、ボトルネックを特定して改善します。これにより、生産効率を最大化し、コストを削減します。
予知保全のデータフロー図(センサーデータの収集から故障予測まで)
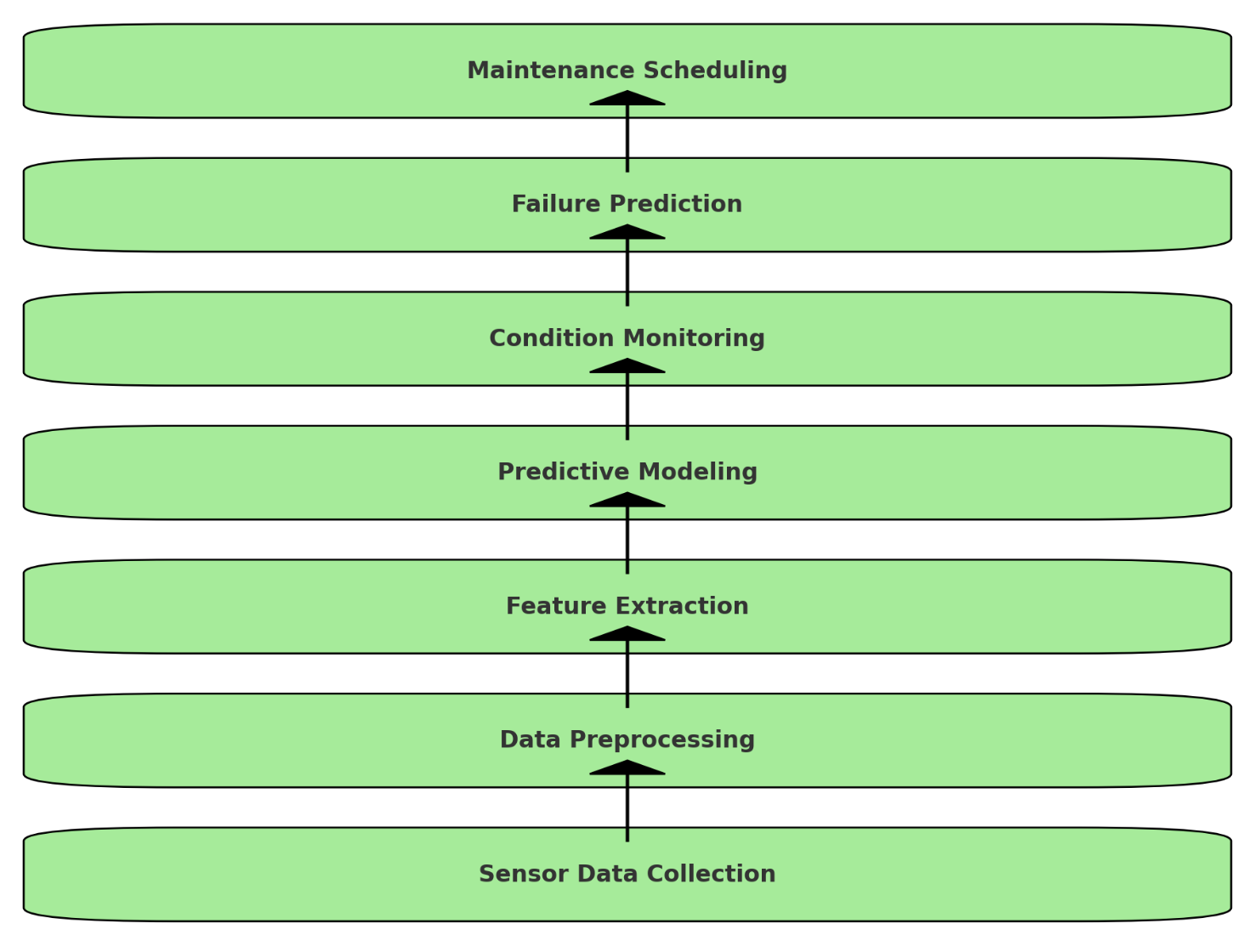
-
Sensor Data Collection: センサーデータの収集
-
Data Preprocessing: データの前処理
-
Feature Extraction: 特徴抽出
-
Predictive Modeling: 予測モデルの構築
-
Condition Monitoring: 状態監視
-
Failure Prediction: 故障予測
-
Maintenance Scheduling: 保全スケジューリング
5. データマイニングのツールとソフトウェア
データマイニングには、さまざまなツールとソフトウェアが利用されています。以下に、代表的なオープンソースツール、商用ソフトウェア、プログラミング言語とライブラリを紹介します。
5.1 オープンソースツール
オープンソースツールは、自由に利用できるデータマイニングのためのソフトウェアであり、広範なコミュニティによってサポートされています。
RapidMiner RapidMinerは、データマイニングと機械学習のための強力なプラットフォームです。ドラッグ&ドロップのインターフェースを持ち、コードを書くことなく複雑なデータ解析を行うことができます。
主要な機能
- データ準備:データの取り込み、クリーニング、変換を簡単に行えます。
- モデリング:多種多様なアルゴリズムを利用してモデルを構築、評価できます。
- 可視化:データとモデルの結果を視覚的に表示し、分析をサポートします。
WEKA WEKAは、ニュージーランドのワイカト大学が開発したデータマイニングソフトウェアで、教育や研究に広く利用されています。Javaで実装されており、多数の機械学習アルゴリズムを提供しています。
主要な機能
- データ前処理:データのフィルタリングや変換を簡単に行えます。
- アルゴリズム:分類、回帰、クラスタリング、アソシエーションルールなど、さまざまなアルゴリズムを利用できます。
- 視覚化:データの可視化ツールを備えており、直感的な分析が可能です。
5.2 商用ソフトウェア
商用ソフトウェアは、企業向けに提供されるデータマイニングツールで、高度な機能とサポートを備えています。
SAS(Statistical Analysis System) SASは、統計解析とデータマイニングの分野で長い歴史を持つ商用ソフトウェアです。高度な分析機能を提供し、企業の意思決定をサポートします。
主要な機能
- データ管理:大規模データセットの取り扱いが容易で、データの準備とクリーニングが効率的に行えます。
- 予測分析:強力な予測モデリングと分析機能を提供します。
- レポート作成:高度なレポート作成ツールを備えており、結果を分かりやすく共有できます
IBM SPSS Modeler IBM SPSS Modelerは、データマイニングと予測分析のための商用ソフトウェアで、使いやすいビジュアルインターフェースを提供しています。
主要な機能
- データ準備:ドラッグ&ドロップでデータの準備が簡単に行えます。
- モデル構築:さまざまな機械学習アルゴリズムを利用してモデルを構築、評価できます。
- 導入:構築したモデルを簡単に実装し、ビジネスプロセスに統合できます。
5.3 プログラミング言語とライブラリ
プログラミング言語とライブラリは、柔軟で強力なデータマイニングのためのツールです。開発者はこれらを使用して、カスタムソリューションを構築できます。
Python Pythonは、データサイエンスと機械学習の分野で広く利用されているプログラミング言語です。豊富なライブラリとフレームワークを備えています。
主要なライブラリ
- Pandas:データ操作と解析のためのライブラリで、データの読み込み、クリーニング、変換を簡単に行えます。
- Scikit-learn:機械学習ライブラリで、分類、回帰、クラスタリングなど、多様なアルゴリズムを提供しています。
- TensorFlow/Keras:ディープラーニングフレームワークで、複雑なニューラルネットワークの構築とトレーニングをサポートします。
Pythonコードの例
このコードは、Irisデータセットを使用して、データの可視化、モデルの学習、評価を一連の流れで行う例です。データサイエンスと機械学習の基本的なプロセスを学ぶのに役立ちます。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# データセットの読み込み
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
# データの基本統計量
print(df.describe())
# データの可視化
sns.pairplot(df, hue='species')
plt.show()
# データの分割
X = df.drop('species', axis=1)
y = df['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの学習
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# 予測
y_pred = clf.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# 詳細な評価レポート
print('Classification Report:')
print(classification_report(y_test, y_pred))
# 混同行列の表示
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
R Rは、統計解析とグラフィックスのためのプログラミング言語で、データマイニングにも広く利用されています。
主要なライブラリ
- dplyr:データ操作のためのライブラリで、データのフィルタリング、変換、集計を効率的に行えます。
- caret:機械学習のトレーニングと評価をサポートするパッケージで、多くのアルゴリズムにアクセスできます。
- ggplot2:データの視覚化のための強力なライブラリで、美しいグラフやプロットを作成できます。
Rコードの例
# 必要なライブラリのインストールと読み込み
install.packages("ggplot2")
install.packages("caret")
install.packages("e1071") # caretパッケージの一部としてSVMを使用する場合に必要
library(ggplot2)
library(caret)
library(e1071)
# データセットの読み込み
data(iris)
# データの基本統計量
summary(iris)
# データの可視化
pairs(iris[,1:4], col=iris$Species)
# データの分割
set.seed(42)
trainIndex <- createDataPartition(iris$Species, p = .8,
list = FALSE,
times = 1)
irisTrain <- iris[ trainIndex,]
irisTest <- iris[-trainIndex,]
# モデルの学習
model <- train(Species ~ ., data = irisTrain, method = "rpart")
# モデルのプロット
plot(model$finalModel)
text(model$finalModel)
# 予測
predictions <- predict(model, newdata = irisTest)
# 精度の評価
confusionMatrix(predictions, irisTest$Species)
6. データマイニングの課題と未来
6.1 プライバシーと倫理の問題
データマイニングは、プライバシーや倫理に関する課題を伴います。大量のデータを扱うため、個人情報や機密データが含まれることがあり、不適切な利用やデータ漏洩のリスクが存在します。
主要な課題
- 個人情報保護:個人データを収集、処理、保存する際に、適切なプライバシー保護対策を講じる必要があります。GDPRやCCPAなどの規制を遵守することが重要です。
- データの匿名化:データを匿名化し、個人を特定できないようにすることで、プライバシー保護を強化します。ただし、匿名化されたデータも、再識別されるリスクがあります。
- 倫理的な利用:データマイニングの結果を公正かつ倫理的に利用することが求められます。差別的なアルゴリズムやバイアスのある分析を避けるために、透明性と公正性を確保する必要があります。
プライバシー保護のフローチャート(データ収集から匿名化までのプロセス)
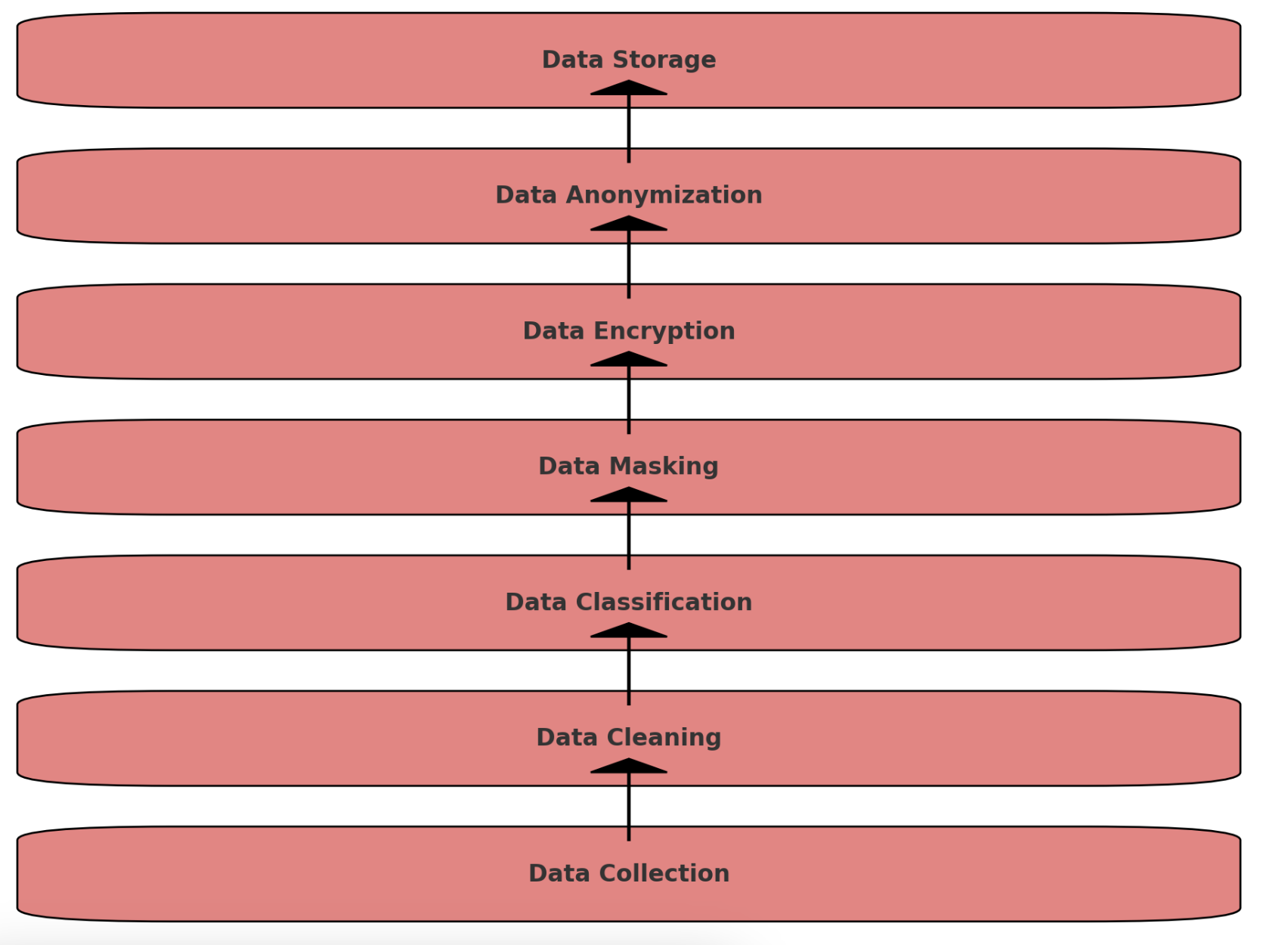
-
Data Collection: データの収集
-
Data Cleaning: データのクレンジング
-
Data Classification: データの分類
-
Data Masking: データのマスキング
-
Data Encryption: データの暗号化
-
Data Anonymization: データの匿名化
-
Data Storage: データの保存
6.2 ビッグデータとリアルタイム分析
データの量と多様性が増加する中、ビッグデータの処理とリアルタイム分析が重要な課題となっています。従来のデータマイニング技術では、大規模データの効率的な処理が難しい場合があります。
主要な課題
- スケーラビリティ:大規模データセットの効率的な処理には、スケーラブルなアルゴリズムとインフラが必要です。分散処理やクラウドコンピューティングの利用が一般的です。
- リアルタイム分析:データがリアルタイムで生成される環境では、即時のデータ処理と分析が求められます。ストリームデータ処理技術が重要です。
6.3 AIとの統合と発展
データマイニングは、人工知能(AI)と機械学習と密接に関連しています。これらの技術を統合することで、データ解析の精度と効率が向上します。
主要な課題
- アルゴリズムの高度化:AIと機械学習アルゴリズムの進化に伴い、より高度なデータマイニング技術が求められます。ディープラーニングなどの新しい技術の導入が進んでいます。
- 自動化と自律化:データマイニングプロセスの自動化と自律化が進んでおり、人的介入を最小限に抑えながら、高度な解析が可能です。AutoMLや強化学習などの技術が注目されています。
- 解釈可能性:AIモデルの複雑さが増す中で、結果の解釈可能性を確保することが重要です。モデルの透明性と説明可能性を維持するための技術開発が進んでいます。
7. 結論
データマイニングは、ビジネスや科学の分野で不可欠な技術となっており、その重要性はますます高まっています。データマイニングのプロセスと技法を理解し、適切なツールとアルゴリズムを利用することで、データから価値あるインサイトを引き出し、意思決定を支援することが可能です。
未来の展望 データマイニングは、ビッグデータやAIとの統合により、さらに発展していくでしょう。プライバシーや倫理の問題に対処しつつ、新しい技術を導入することで、より高度で効率的なデータ解析が実現されます。企業や研究者は、この進化を活用して、競争力を高め、社会に貢献する新たなソリューションを提供することが期待されます。
**AIやデータサイエンスのプロジェクトに関心がある場合や、クラウドサービスの導入を検討している場合は、ぜひ弊社にご相談ください。**私たちの専門知識と経験を活かし、貴社のビジネス成功に貢献する最適なソリューションをご提案いたします。
お問い合わせは、こちらからお気軽にどうぞ。