💡 ElcamyではGoogle Cloudを用いたデータ分析基盤の構築や、生成AIを用いた業務支援まで対応可能です。生成AIやデータ活用によって事業を前に進めたい方は、お気軽にご相談ください。
1. はじめに
こんにちは、今回の筆者はElcamyデータサイエンティスト兼AIエンジニアの近江俊樹です。
現在、データサイエンティストはビジネスや研究の現場で欠かせない存在となっています。
ビッグデータの時代において、膨大なデータを分析し、そこから価値ある情報を抽出する能力は非常に重要です。
要するに一人や複数の人間の脳みそではもう考えることが難しいくらいの情報量を扱いたい場合はデータサイエンスを「学ぶ」もしくは「使う」しかないということです。
ChatGPTやその他AIツールを使ってもある程度のことはできますが、高度な内容・非常に多い情報量・暗黙知が必要とされる場合はデータサイエンスに詳しくないといけません。
※暗黙知とは
個人の経験則や勘に基づくノウハウ、仕事を重ねる中で身につけたスキルといった、社員それぞれの中にある言語化されていない主観的なナレッジ。
筆者個人の感想ですが、暗黙知をいかに言語化し、形式知にできるかがAI時代の今、求められている力だと思います。その力がなければ、AIに適切な指示を出すことができないからです。
例えば「いい感じの会社名を考えて」と伝えても「いい感じ」を「検索されやすい」、「何をやっているかイメージできる」、「思いが伝わる」などに分解し、「思いが伝わる」というのもさらに分解しないといけないと思います。トヨタの**なぜなぜ分析**に近いですね。
出典:暗黙知と形式知とは?
未経験からでもデータサイエンティストを目指せる理由としては、以下のようなポイントが挙げられます。
- データサイエンティストの需要は年々増加
- 企業はデータを活用して競争力を高めることを目指しているので今後も需要増加が見込める
- オンラインコースや記事が充実しているため、独学でスキルを身につけることが可能
さらに、データサイエンスの分野は幅広いため、自分の興味や強みに合わせた専門分野を選択することができるというメリットもあります。
例えば、機械学習、データエンジニアリング、ビジネスインテリジェンスなど、さまざまなキャリアパスがあります。
2. データサイエンスの基礎知識
データサイエンスとは、大量のデータを収集、整理、分析し、そこから有用な情報やパターンを見つけ出す学問領域です。
これには、データの前処理、統計分析、機械学習モデルの構築、データの可視化など、さまざまなプロセスが含まれます。
データサイエンティストの仕事内容
データサイエンティストの具体的な仕事内容は、多岐にわたります。一般的には以下のようなタスクを行います。
- データ収集と前処理 データを収集するための適切な方法を選択し、データクレンジングを行います。データクレンジングでは、欠損値の処理や異常値の除去などが含まれます。
- データの探索と分析 データの基本的な統計量を計算し、データの分布や相関関係を理解します。この段階では、データの傾向やパターンを把握するために、様々な可視化手法(グラフやヒストグラムなど)を用います。
- モデルの構築と評価 収集したデータをもとに、機械学習モデルや統計モデル(わかりやすくざっくり言ってしまうと、人工的に作った「脳みそ」)を構築します。モデルの精度を評価し、改善するための手法を適用します。ここでは、過学習やアンダーフィッティングの回避が重要です。
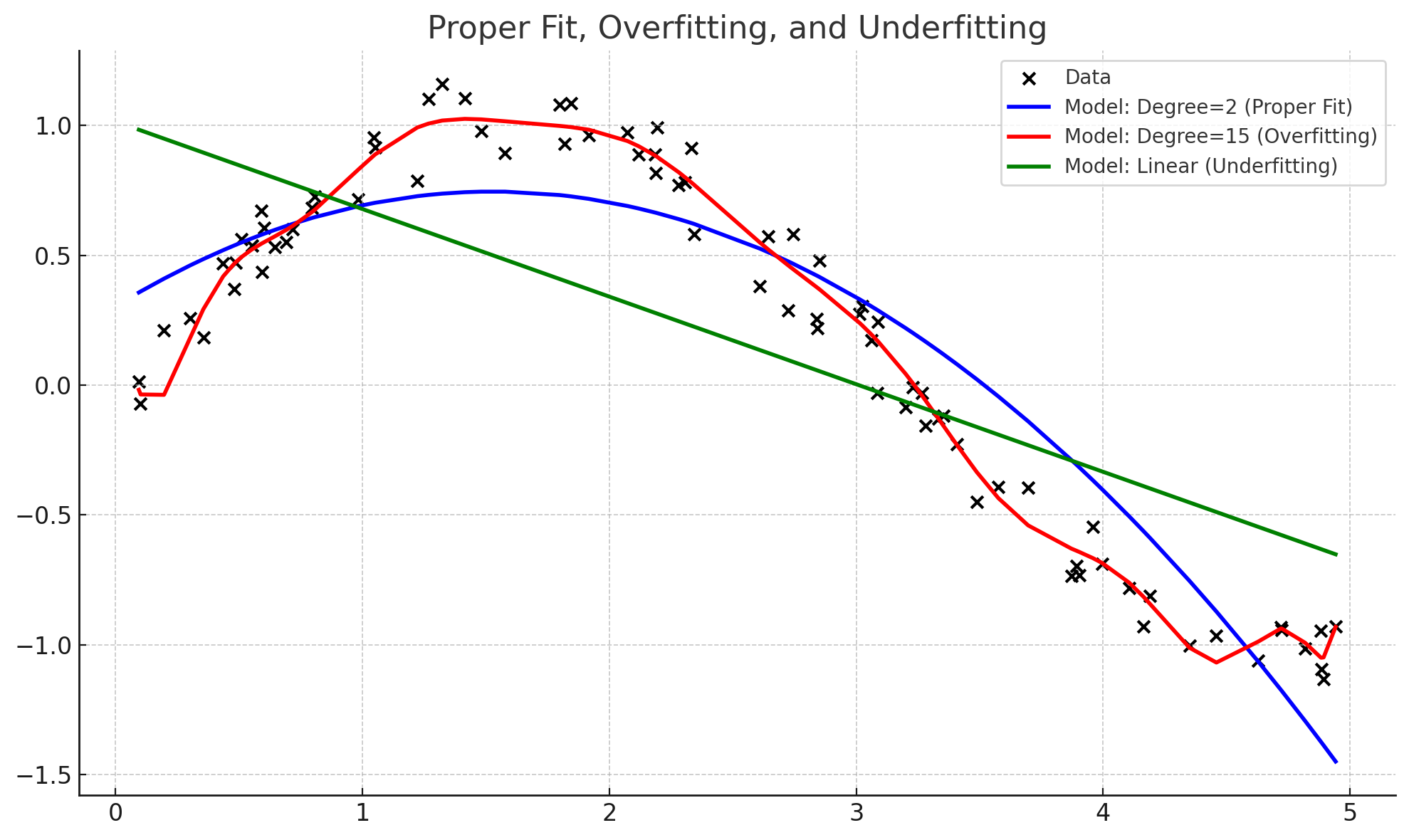
×印:データ
赤線: 過学習、学び過ぎてしまい点を結んでいるだけのような何の参考にもならないグネグネとした線 (例)頭が硬く少しのイレギュラーにも敏感に反応してしまい物事の本質を掴めない人
緑線: アンダーフィッティング、ざっくりと学んでしまったために、あまり参考にならない線 (例)物事をあまりに端的に捉えてしまい本質を見誤って掴んだつもりになっている人
青線: 程よく学んでいるので綺麗な曲線となっており、ちょうどいい(これを目指したい) (例)いわゆるセンスが良いと呼ばれる人たち 4. 結果の解釈と報告 分析結果をわかりやすく報告するために、プレゼンテーション資料やレポートを作成します。この時に、上記の青線の状態ですと、ビジネスの意思決定者に対して、データに基づく提案をスムーズに行えます。 5. 継続的なモデルの運用と改善 データサイエンスのプロジェクトは、一度で終わるものではありませんですし、一発でできるものでもありません。「3モデル構築」で綺麗に思われる青線であっても、そのプロジェクトにとって非常に大事な×(データ)からかけ離れている場合もあります。都度モデルの性能をモニタリングし、新しいデータが入るたびにモデルを再訓練することが求められます。
インサイト(ひらめきや発見)というのは、現場の感覚とデータの掛け合わせで見つかることが多いです。
つまりデータサイエンティストとは、ビジネスの問題をデータの視点からだけ解決するのではなく、現場のビジネス理解やそれを捉えるためのコミュニケーション能力も非常に重要です。
3. 必要なスキルセット
データサイエンティストになるためには、多岐にわたるスキルが求められます。
ここでは、基本的なスキルセットについて説明します。
💡 これ以降はデータサイエンティストになろうと心に誓った方のみ読んでいただければ結構です。ここから先はサポートベクターマシンやPandasなどといった用語解説はしませんので、独力でわからないことがあったら調べていただき、調べる癖(自分なりの調べ方のフロー構築)を確立してください。 といっても4. 学習方法 でご紹介する書籍でほとんど学べると思いますので、この記事では雰囲気を掴んで読み進める程度でも問題ありません。
プログラミング言語
Python Pythonはデータサイエンスで最も使用されるプログラミング言語です。豊富なライブラリ(NumPy, Pandas, Scikit-learn, TensorFlowなど)があり、データ処理から機械学習モデルの構築まで幅広く対応しています。
R Rもデータ分析や統計処理に特化した言語で、多くの統計学者やデータサイエンティストに利用されています。ggplot2などの強力な可視化ツールがあり、データの視覚化に優れています。
統計学
データサイエンスの中心には統計学があり、データの理解や分析に不可欠です。基本的な統計学の概念(平均、中央値、分散、標準偏差、相関係数など)を理解することが重要です。また、回帰分析や仮説検定などの高度な統計手法も必要になります。
数学
機械学習の理論を理解するためには、線形代数や微積分の基礎知識が必要です。特に、行列演算や勾配降下法など、機械学習アルゴリズムの基礎となる数学的概念を理解しておくことが求められます。
データベースとSQL
データは多くの場合、データベースに格納されています。SQL(Structured Query Language)は、データベースからデータを取得、操作するための言語です。データの抽出、結合、フィルタリングなど、基本的なSQLクエリの書き方を習得することは重要です。
機械学習の基本概念
機械学習は、データから自動的にパターンや規則を学び取る技術です。基本的な機械学習アルゴリズム(線形回帰、ロジスティック回帰、決定木、ランダムフォレスト、サポートベクターマシンなど)を理解し、実装する能力が求められます。
深層学習 特に近年は、深層学習(ディープラーニング)が注目されています。深層学習は、多層のニューラルネットワークを用いてデータを処理する技術で、画像認識や自然言語処理など、多くの分野で活用されています。TensorFlowやPyTorchといったフレームワークを使って、深層学習モデルを構築するスキルも重要です。
4. 学習方法
データサイエンティストになるためのスキルを習得するためには、多くの学習が必要です。
以下におすすめの書籍やWEBページを載せました。
上から順に進めることをおすすめします。
おすすめの書籍
- Python:現役シリコンバレーエンジニアが教えるPython(書籍)
- データサイエンス:東京大学のデータサイエンティスト育成講座(書籍)
- 実践データ分析:実践データ分析100本ノック(書籍)
- 深層学習:深層学習モデル・AIアプリ開発入門(書籍)
- SQL:SQL100本ノック(このnoteにやり方が載っています)
- 統計学:統計学の基礎から応用まで(WEBページ)
※上記全てに言えることですが、わからないことは調べたりChatGPTに聞いても大丈夫です。ただし全てを鵜呑みにするのではなく理解しながら進めることが重要です。
5. 実務経験を積む方法
データサイエンスのスキルを学んだ後、実際のプロジェクトでそれを活用する経験を積むことが重要です。ここでは、実務経験を積むための具体的な方法を紹介します。
インターンシップ
インターンシップは、実際の企業で働くことでデータサイエンスの実務経験を積む絶好の機会です。多くの企業がデータサイエンスに関するインターンシップを提供しており、特にテクノロジー企業やスタートアップでは、データサイエンティストのインターンシップの募集が頻繁に行われています。
Greenや企業のキャリアページを定期的にチェックし、興味のあるポジションに応募しましょう。
Kaggleなどのコンペティション
Kaggleは、データサイエンスのコンペティションプラットフォームであり、実際のデータセットを使ってさまざまな問題を解決することができます。コンペティションに参加することで、実際のビジネス課題に取り組む経験を積むことができます。また、他の参加者と交流することで、最新の技術やトレンドを学ぶこともできます。
初心者向けのコンペティション Kaggleには初心者向けのコンペティションも多くあります。例えば、「Titanic: Machine Learning from Disaster」などのコンペティションは、機械学習の基本的なスキルを実践するための良いスタートです。
オープンソースプロジェクトへの参加
GitHubなどのプラットフォームで公開されているオープンソースプロジェクトに参加することで、実際のデータサイエンスプロジェクトの経験を積むことができます。他の開発者と協力してプロジェクトを進めることで、チームでの作業やコードレビューの経験も得られます。
プロジェクトの探し方 GitHubで「data science」や「machine learning」などのキーワードで検索すると、多くのオープンソースプロジェクトが見つかります。興味のあるプロジェクトに貢献することで、実践的なスキルを磨くことができます。
6. キャリア構築のための簡単なアドバイス
データサイエンティストとしてのキャリアを成功させるためには、スキルの習得だけでなく、効果的なキャリア戦略も必要です。ここでは、レジュメとポートフォリオの作成、ネットワーキング、面接対策について詳しく説明します。
レジュメとポートフォリオの作成
レジュメの作成 データサイエンティストのレジュメは、具体的なスキルセットと実績を明確に示すことが重要です。以下のポイントに注意して作成しましょう。
- スキルセクション
- プログラミング言語(Python, R)
- ツールとライブラリ(Pandas, numpy, matplotlib等)
- データベースとSQLの知識
- 統計学と数学の基礎
- プロジェクト経験
- Kaggleのコンペティション参加経験
- インターンシップでのプロジェクト
- GitHubに公開しているオープンソースプロジェクト
- 業績と成果
- データ分析や機械学習モデルの構築で得られた具体的な成果
- ビジネスへの貢献度(売上向上、コスト削減など)
ポートフォリオの作成 ポートフォリオは、実際のプロジェクトや成果物を示すための重要なツールです。以下の内容を含めると良いでしょう。
- プロジェクト概要
- プロジェクトの目的と背景
- 使用した技術とツール
- アプローチと手法
- データ収集と前処理の方法
- 分析手法と機械学習モデルの詳細
- 成果とインサイト
- 得られた結果とそれに基づくインサイト
- ビジュアル(グラフやチャートなど)を使って成果をわかりやすく示す
面接対策と模擬面接
データサイエンティストの面接では、技術的なスキルだけでなく、問題解決能力やコミュニケーションスキルも評価されます。
技術的な質問の準備
- コーディングテスト:PythonやRを使ったコーディングテストの準備をしましょう。
- 統計学と機械学習の質問:基本的な統計学の概念や機械学習アルゴリズムについて説明できるように準備しましょう。
面接の準備
-** STARメソッド:**Situation(状況)、Task(課題)、Action(行動)、Result(結果)を整理して話す練習をしましょう。過去のプロジェクトや経験を具体的に説明できるように準備します。
7. まとめ
データサイエンティストとしてのキャリアを築くためには、継続的な学習と成長が重要です。
新しい技術や手法が次々と登場するため、常に最新の情報をキャッチアップし続けることが求められます。
未経験からデータサイエンティストになる道はハードルが高いと思われますが、計画的な学習と実践を繰り返すことで確実に道を切り拓くことができます。
Elcamyでは一緒に働く仲間を募集しています。
カジュアル面談も随時行なっております。
Elcamyについてお知りになりたい方はどうぞお気軽にお問い合わせください。