皆さん、こんにちは。
今回の筆者は株式会社Elcamyのデータサイエンティスト兼AIエンジニアの近江です。
最近は「ChatGPT」のようなAIサービスが話題になっていますよね。ニュースやSNSでもAIの話題を見ない日はないほど、AIは僕たちの生活のすぐそばまで来ています。
まるでSF映画の世界が現実になったみたいでワクワクしませんか?僕も毎日、新しい技術に触れるたびにワクワクが止まりません。
特に注目されているのが「LLM(大規模言語モデル)」
LLMの略は「Large Language Models」です。
これは、AIに人間のような自然な文章を理解させたり、生成させたりするための技術です。
ChatGPTがまるで人間と話しているように自然な受け答えができるのも、このLLMのおかげです。
「LLMって難しそうだなぁ…。」
そう思った方もいるかもしれません。確かに、専門的な知識も多いので、難しそうと感じてしまうのも無理はありません。
しかし、 LLMは、AIの可能性を大きく広げる技術なのです。
そして、AI時代を生き抜くためには、LLMに対する理解を深めていくことが非常に大切になってきます。
そこで今回は、皆さんにLLMをより身近に感じてもらい、AI時代を自信を持って歩めるように、LLMの基礎から応用、そして未来までを分かりやすく解説していきます。
💡 ElcamyではGoogle Cloudを用いたデータ分析基盤の構築や、生成AIを用いた業務支援まで対応可能です。生成AIやデータ活用によって事業を前に進めたい方は、お気軽にご相談ください。
1. 導入:LLMってどんな技術?
1.1 改めて、大規模言語モデル(LLM)とは?
LLM(Large Language Model:大規模言語モデル)
平たくいうと「めっちゃ賢くて、言葉に強いモデル(モデルとは何かは後述します。今は「仕組み」と捉えておいてください)」です。
僕たち人間のように、自然な文章を理解したり、作ったりすることが得意です。
例えば、
- 詩や小説、脚本のようなクリエイティブな文章だって書けちゃう
- 外国語の翻訳もAIにおまかせ!
- 長文を要約したり、重要なポイントを抜き出したりすることも得意なんです。
まるで優秀な秘書みたいですよね。
LLMの構成要素は簡単に説明すると以下3つとなります。
-** ニューラルネットワーク **人間の脳を模倣した数学モデルで、大量のデータを処理し、特徴を抽出します。
- トランスフォーマー(Transformer:後述します)** LLMの基盤となる技術で、文脈を深く理解し、単語間の関係を捉えることができます。 - 事前学習とファインチューニング **まずは大量のテキストデータを学習し(事前学習)、その後、特定のタスクに特化して学習することで(ファインチューニング)、高精度なモデルを構築します。
またLLMの「大規模」は、主に以下の3つの要素が非常に大規模であることを指します。言語をたくさん知っているという意味は正確ではありません。
- パラメータ数 パラメータはニューラルネットワーク(人間の脳を模倣した数学モデル)の構成要素です。 このモデルを構成するパラメータ(重みとバイアス)の数が多いほど、より複雑なパターンを学習し、表現することができます。 重みとバイアスをかなり簡単に説明すると(正確性には欠く)、「りんご」と聞いたら「赤」「食べる」「おいしい」などが頭にパッと浮かぶようなイメージで、もし「りんご」の次に「食べる」という単語が来たらスッと理解できますよね。「りんご」は「面白い」と来たら一部の方は物理の話かな?と思うようなものです。逆に「りんご」は「紙」と来たらちょっとよくわからないかもしれません。人間は割と自然にやっていますね。 若干脱線してしまいますが、分かりやすい話し方をする人は自然とこれをやってのけていたり、上級者はあえて「りんご」「紙」のような話し方を始めて聴衆の注意を向けるということをやったりしています。
ニューラルネットワークの重みとバイアスの詳細を知りたい方
改めてニューラルネットワークは、人間の脳の神経回路を模倣した数学モデルです。このモデルの中で、重みとバイアスは、ニューロン間の接続の強さや、ニューロンの出力に影響を与える重要なパラメータです。
重みとは?
- ニューロン間の接続の強さ: ニューラルネットワークでは、ニューロン同士が互いにつながっており、あるニューロンの出力値が次のニューロンの入力値に影響を与えます。この時の影響の度合いを「重み」と呼びます。
- 重みの役割: 重みが大きいほど、前のニューロンの出力値が次のニューロンの出力値に大きく影響します。逆に、重みが小さいほど、影響は小さくなります。
- 学習による変化: ニューラルネットワークの学習過程では、この重みが調整されることで、ネットワーク全体の出力値が目標とする値に近づくようにします。
バイアスとは?
- ニューロンの出力値へのオフセット: バイアスは、ニューロンの出力値に一定の値を加えることで、出力値を調整する役割を果たします。
- 活性化関数の閾値: バイアスは、活性化関数(ニューロンの出力値を非線形に変換する関数)の閾値を調整する効果もあります。
- 学習による変化: 重みと同様に、バイアスも学習によって調整されます。
ニューラルネットワークの重みとバイアスの図
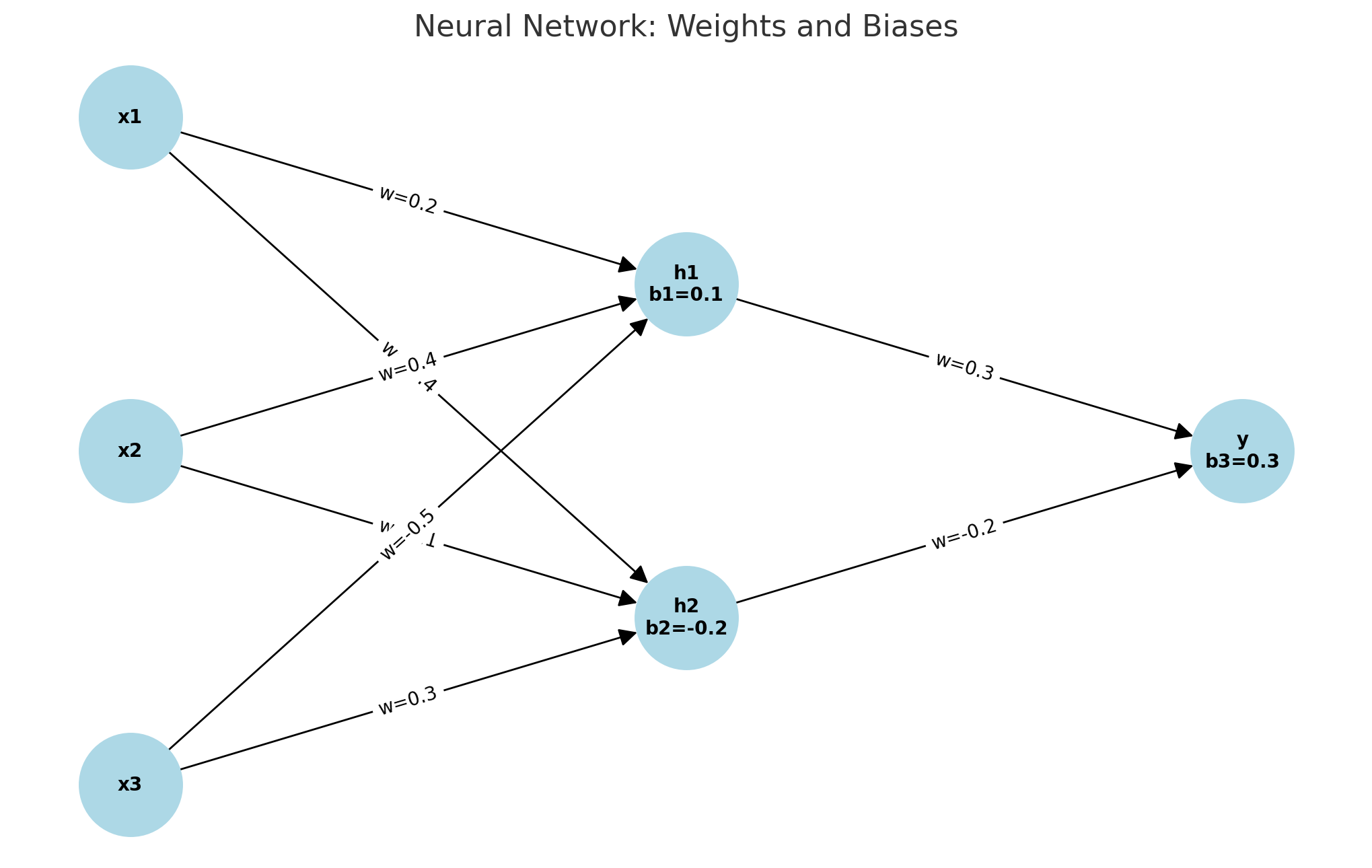
• 入力層 (Input Layer): x_1, x_2, x_3
• 隠れ層 (Hidden Layer): h_1, h_2(バイアス b1=0.1, b2=-0.2 )
• 出力層 (Output Layer): y (バイアス b3=0.3 )
※矢印にはそれぞれの重みが表示されています(例: w = 0.2 )
抽象的な話となってしまいましたので例えば、画像認識のニューラルネットワークを考えてみましょう。
画像の各ピクセルの値が入力層に与えられ、複数の層を経て、最終的に画像の内容(猫、犬など)が分類されます。
- 重み: 各ピクセルの値が、次の層のニューロンにどの程度影響を与えるかを決定します。例えば、猫の画像を認識する際には、猫の耳の部分に対応するピクセルの重みが大きくなるように調整されます。
- バイアス: 各ニューロンの出力値に一定の値を加えることで、ニューロンが活性化しやすくなったり、しにくくなったりします。
まとめ
- 重みは、ニューロン間の接続の強さを表し、ニューラルネットワークの学習によって調整されます。
- バイアスは、ニューロンの出力値にオフセットを加えることで、ニューロンの活性化を調整します。
- 重みとバイアスの適切な組み合わせにより、ニューラルネットワークは複雑なパターンを学習し、様々なタスクをこなすことができます。
さらに
- バックプロパゲーション: ニューラルネットワークの学習で用いられる、重みとバイアスを効率的に調整するアルゴリズムです。
- 活性化関数: シグモイド関数、ReLU関数など、様々な種類があります。
- 過学習: ニューラルネットワークが学習データに過度に適合し、新しいデータに対してうまく一般化できない現象です。
LLMは、このパラメータ数が大規模であり、数十億から数兆を超えるものも珍しくありません。この膨大なパラメータのおかげで、LLMは人間の言語の複雑さを捉え、高度なタスクをこなすことができるのです。 2. 学習データ量 LLMは、膨大な量のテキストデータを学習することで、言語の構造や意味を理解します。 学習データの質も重要ですが、LLMは質の高いデータに加え、大量のデータで学習することで、より汎用的な能力を獲得します。Web上のテキストデータ、書籍、論文など、あらゆる種類のテキストが学習データとして利用されます。 3. 計算資源 LLMの学習や推論には、非常に強力なコンピュータが必要となります。 GPU(Graphics Processing Unit)やTPU(Tensor Processing Unit)などの並列処理に特化したハードウェアが利用されます。これらのハードウェアを用いることで、膨大な計算を高速に行うことができます。
1.2 そもそもAIにおける「モデル」って?
「モデル」と聞いて、何を思い浮かべますか?
ファッションショーでランウェイを歩く美しい「モデル」…。
いえいえ、AIの世界ではちょっと違います。
AIの世界の「モデル」は、簡単に言うと「AIがデータを分析し、未来予測や判別を行うための仕組み」です。
例えば
- 明日の天気予報
- 株価の変動予測
- 手書き文字の認識
など、AIが様々なことを予測したり、判断したりするために、「モデル」は欠かせないものなんです。
人間で例えると思考回路、思考パターン、考え方になるのでしょうか。
例えば、普段小説を書いている人が株価の予測をするときに同じ考え方をしていないとは思います(上級者は境界なく捉えているとは思いますが一旦置いておいて…)
株価を予測しているときは主に数字や期待値などを論理的に考えますが、論理的なまま小説を書いてしまうとおそらくとてもつまらないものとなってしまうと思います。ストーリーの整合性を取る分にはそのような頭の使い方をしても良いですが、ストーリーを広げたり新たな視点で書いていくためには頭を曖昧にさせる必要があると思います。
1.3 LLMはAIの進化に欠かせない存在
LLMは、AIの進化、特に「自然言語処理(NLP:Natural Language Processing)」と呼ばれる分野において、革命的な技術と言われています。
NLPとは、人間が普段使っている言葉をコンピューターに理解させるための技術のこと。
例えば、「今日はいい天気ですね」という言葉をコンピューターに理解させようとした時、人間にとっては当たり前のことでも、コンピューターにとっては非常に難しい問題です。
「今日は」は名詞なのか?「いい天気」とは具体的にどんな状態なのか?といったように、コンピューターは言葉の一つ一つを分解し、分析する必要があるからです。
LLM以前は、このような言語処理がAIにとって大きな壁となっていました。 しかし、LLMの登場によって、人間のように自然な文章を理解し、生成することが可能となり、NLPの分野は劇的に進化したのです。
1.4 LLMの進化を支える「トランスフォーマー(Transformer)」
LLMの進化を語る上で欠かせないのが「トランスフォーマー」という技術です。
トランスフォーマーは、文章内の単語同士の関係性を分析することで、より深く文脈を理解する技術。
例えば、「私は毎日りんごを食べる。」という文章の場合、「私」と「食べる」という動詞は強く関連しており、「りんご」は「食べる」の対象であることを理解します。
従来の技術では、このような文脈理解は非常に困難でしたが、トランスフォーマーによって飛躍的に精度が向上しました。 これはまさに、LLMが人間のように言葉を理解できるようになった秘密兵器と言えるでしょう。
2. LLMの重要性と影響
2.1 様々な分野で活躍するLLM
LLMは様々な分野でその力を発揮しています。
| 分野 | 例 |
|---|---|
| カスタマーサービス | 自動応答システム(チャットボット)による顧客対応の効率化 |
| 教育 | 生徒一人ひとりに合わせた学習教材の作成や、学習進捗に応じたサポート |
| 医療 | 診断支援、創薬、医療記録の自動生成 |
| エンターテイメント | 小説、脚本、音楽などの自動生成 |
| 翻訳 | 高精度なリアルタイム翻訳 |
このように、LLMは僕たちの生活のあらゆる場面で活用され始めています。
2.2 LLMによって変わる未来
LLMの進化は、まさに日日進歩。 近い将来、僕たちの生活はLLMによって大きく変わる可能性を秘めているんです。
例えば、
- AIによる個別指導で、教育の格差が減るかもしれません。
- 翻訳機能がさらに進化することで、海外旅行がもっと身近になるでしょう。
- AIがクリエイティブな仕事もこなせるようになり、新しいエンターテイメントが生まれるかもしれません。
このように、LLMは僕たちの未来をより豊かで便利な方向に変えていく可能性に満ち溢れているんです。
2.3 LLMは諸刃の剣?倫理的な課題
革新的な技術であるLLMですが、その発展には倫理的な課題もつきまといます。
- **バイアスや差別 学習データに偏りがあると、AIが差別的な発言をしてしまう可能性も - プライバシー侵害 個人情報の取り扱いには細心の注意が必要 - 倫理観の欠如 **倫理的に問題のある文章を生成してしまうリスクも
LLMは使い方次第で良くも悪くもなり得ることを忘れてはいけません。
僕たち人間がLLMとどう向き合っていくかが問われているのです。
3. LLMの基礎:どんな仕組みで動いているの?
3.1 LLMの仕組み
LLMは、人間の子供がお言葉を覚える過程とよく似ています。 大量の文章を読み込むことで、言葉のルールやパターンを学習していくのです。
具体的には、以下のようなステップでLLMは賢くなっていきます。ちょっと料理に似てます。
1.** データ収集:食材集める まずは、インターネット上のウェブサイトや電子書籍など、ありとあらゆるテキストデータを大量に集めます。 2. 前処理:食材を調理に合うよう切る 集めたデータはそのままでは使えないので、LLMが理解できるように綺麗に整理します。 3. モデルの学習:煮たり焼いたり料理にあった調理を 整理したデータをLLMに学習させます。この時、LLMは膨大な量のテキストデータから、言葉の並び方や意味、文脈などを学習していきます。 4. ファインチューニング:ちょっと物足りないな、塩を加えて味の調整 **特定のタスク、例えば翻訳や質疑応答など、LLMをどのように使いたいかによって、追加で学習を行います。
3.2 LLMを支える「トランスフォーマーアーキテクチャ」
前述した「トランスフォーマー」は、LLMの頭脳とも言える「アーキテクチャ(構成)」の一つです。
従来のモデルでは、文章を単語ごとに順番に処理していました。 しかし、トランスフォーマーは、文章全体を一度に見渡せるため、単語同士の関連性や文脈をより深く理解することが可能になったのです。
例えるなら、従来のモデルは、文章を一文字ずつ追っていく「虫眼鏡」のようなもの。 一方、トランスフォーマーは、文章全体を一度に見渡せる「広角レンズ」のようなものです。 どちらがより深く文脈を理解できるかは、一目瞭然ですよね。
3.3 大量のデータで鍛え上げられた「学習済みモデル」
LLMのすごいところは、一度学習を終えれば、その後は新しいデータを追加しなくても、様々なタスクに対応できるようになること。
例えば、大量のテキストデータを学習したLLMは、翻訳や質疑応答、文章生成など、様々なタスクに高いレベルで対応できるようになります。 これは、まるでスポーツ選手が厳しいトレーニングを積み重ねることで、様々な競技に対応できるようになるのと同じです。
このような学習を終えたLLMを「学習済みモデル」と呼びます。 僕たちが普段利用しているChatGPTなども、この学習済みモデルの一つです。
最近、私個人の趣味で洋服の種類を判断する画像認識モデルを1から開発し、そのモデルを元に洋服の画像判定アプリを作ってみましたが、Tシャツのみの画像であれば精度は高いですが、人が来ている状態のTシャツの画像だと精度が落ちて調整するのが大変でした。
ちなみにGPTに「これは何の洋服ですか?」と聞いたら「これは白いTシャツですね。とてもよく似合ってます。」と気の利いた一言まで言ってくれました。
4. 代表的なLLM:GPT-4、BERTそして…(2024年7月26日時点)
4.1 OpenAIが開発した「GPTシリーズ」
LLMの中でも、特に注目されているのが、OpenAI社が開発した「GPTシリーズ」です。 GPTは「Generative Pre-trained Transformer」の略称で、その名前の通り、トランスフォーマー技術を用いて開発された、非常に高性能なLLMです。
現時点で最新モデルは「GPT-4」ですが、その一つ前のバージョンである「GPT-3」も、当時としては圧倒的な性能で世界を驚かせました。
| モデル | パラメータ数 | 特徴 |
|---|---|---|
| GPT-3 | 1750億 | 人間らしい自然な文章生成能力、多様なタスクへの対応 |
| GPT-4 | 非公開(性能などからの推測では1.8兆) | GPT-3よりもさらに高性能。画像認識、多言語翻訳、高度な推論能力など、幅広い能力を有する。 |
GPTシリーズは、様々なタスクをこなせるのが最大の特徴です。 例えば、
- **ブログ記事や小説、詩などの創作活動 より創造的で多様なコンテンツ生成が可能になりました。 - プログラミングコードの生成 より複雑なコードの生成、デバッグ、説明までをこなせるようになっています。 - 会話形式での質疑応答 より自然で人間らしい会話、専門知識に基づいた回答が可能になりました。 - 翻訳 **多言語間の高品質な翻訳、異なるスタイルの翻訳への対応など、翻訳の精度が向上しています。
など、その応用範囲は多岐に渡り、日々新たな可能性が開かれています。
4.2 Googleが開発した「BERT」そして…「Gemini」
BERT(Bidirectional Encoder Representations from Transformers)は、Googleが開発したLLMです。 GPTシリーズが「文章を自動生成する」ことに力を入れているのに対し、BERTは「文章の意味を正確に理解する」ことに特化しているのが特徴です。
BERTは、検索エンジンの検索結果の精度向上、質問応答システム、感情分析など、自然言語処理の様々な分野で活用されています。また、BERTをベースとした様々なモデルが開発されており、LLMの発展に大きく貢献しています。
「Gemini」とはGoogleが開発した、非常に強力な大規模言語モデル(LLM)です。従来のLLMを大きく凌駕する性能と、多様なタスクに対応できる汎用性の高さから、AI業界で大きな注目を集めています。
Gemini、日本ではジェミニと言われているが、英語ではジェミナイと発音されています。
Geminiはラテン語で「双子」を意味する言葉です。日本ではずっとジェミニと呼ばれているので、何のことやらと思っていましたが、Googleの英語教材を進めていたときに「ジェミナイ!」と発音していたので、その瞬間、僕は遊戯王の「ジェミナイエルフ」をスッと思い出し完全に理解できました。
GPTとGeminiをよく使っている私の感想としては、GPTは人間の曖昧な問いやお願いに対して結構良い回答をしてくれます。将来iPhoneに搭載されるらしいので、相性良さそうですね。
ただ倫理的な問題だったり、回答のソース元が何も言わず最新のものにしてくれたり、文章を書き直してくれる能力は感覚的なものですが、Geiminiの方が良いかなと思ってます。ただちょうど昨日、SearchGPTというのが出るよという予告があったので、どうなるか分かりません。
僕は何かを作成するとき
GPTに0→30%、Geminiに30→60%までやってもらい、残り60→100%は自分(近江言語モデル)で処理してますね。
GPTはこちらから利用できます。
Geminiはこちらから利用できます。
5. LLMの応用:僕たちの生活はどう変わる?
5.1 自然言語処理(NLP)の進化
LLMは、自然言語処理(NLP)の分野において、これまでとは比べ物にならないほどの進化をもたらしました。
NLPとは、人間が普段使っている言葉をコンピューターに理解させるための技術のことです。
LLMの登場により、以前は難しかった複雑な言語処理が可能となり、AIはより人間に近い形で言葉を扱えるようになってきています。
5.2 LLMが活躍する様々な領域
LLMは、様々な分野でその領域を発揮しています。
| 領域 | 説明 |
|---|---|
| 文章生成 | ブログ記事や小説、詩、脚本、広告コピーなどをプロのライターのように生成。時間と労力を削減し、斬新なアイデアも生み出せる。 |
| 翻訳 | 自然で高精度な翻訳を実現。ビジネス、教育、文化交流などでグローバルなコミュニケーションを促進。 |
| 感情分析 | 文章に込められた感情を読み解き、顧客満足度向上の施策に役立てる。顧客レビューやSNS投稿の分析に有用。 |
| 質疑応答 | 質問に合致する最適な回答を瞬時に探し出す。カスタマーサポートの自動化や社内情報共有の効率化に期待される。 |
| コード生成 | プログラミングコードを生成。コーディング作業を効率化し、バグの発生を抑え、質の高いコードを開発することが可能。 |
6. LLMの課題と問題点:進化の裏側にある「影」
革新的な技術であるLLMですが、その進化の過程では、いくつかの課題や問題点も浮き彫りになってきました。 ここでは、LLMが抱える「影」の部分について、詳しく解説していきます。
6.1 莫大な計算資源とコスト
LLMのトレーニングには、非常に高度な計算能力と膨大なデータ量が必要となります。 例えば、GPT-3のトレーニングには、数百億円規模の費用がかかったと言われています。
このように、LLMの開発には莫大なコストがかかるため、資金力のある大企業や研究機関だけがLLM技術を独占してしまう可能性も懸念されています。
6.2 バイアスと倫理問題
LLMは、インターネット上の膨大なデータから学習するため、データに偏りがあると、それがそのままAIの出力に反映されてしまう可能性があります。
例えば、
- 性別や人種、宗教などに関する差別的な発言
- 特定の政治思想を支持するような発言
など、倫理的に問題のある発言をしてしまうリスクも孕んでいるのです。
LLMを開発する側は、倫理的な問題を引き起こさないよう、学習データの選定やモデルの調整など、様々な対策を講じる必要があります。
6.3 データプライバシー
LLMのトレーニングには、個人情報を含むデータが使用される可能性もあるため、プライバシー保護の観点からも、十分な注意が必要です。
データの匿名化やアクセス制限など、適切なセキュリティ対策を施し、個人情報が漏洩するリスクを最小限に抑える必要があります。
6.4 説明可能性の欠如
LLMは、複雑な計算処理によって出力を生成するため、なぜその結論に至ったのか、そのプロセスを人間が理解することは非常に困難です。
これは「ブラックボックス問題」とも呼ばれており、医療診断や自動運転など、人命に関わる重要な意思決定にLLMを活用する場合には、大きな課題となります。
7. 未来の展望:LLMは僕たちの未来をどう変える?
7.1 モデルのさらなる進化
-** 軽量化 より少ない計算資源で高性能なモデルを開発することで、LLMの利用をより身近なものにする取り組みが進んでいます。 - マルチモーダル化 **テキストだけでなく、画像、音声、動画など、様々な種類のデータを統合的に理解できるLLMの開発がさらに進められています。
7.2 新しい技術との融合
-** メタバース **仮想空間上に構築されたメタバースにおいて、LLMは、ユーザーと自然な対話を行うAIエージェントの実現に貢献することが期待されています。メタバース上に新人類を生み出せてしまうようなイメージです。
- DAO(分散型自律組織) LLMの回答がバイアスや倫理問題、プライバシーに配慮したものであるかどうかの監査手続きを行うことができれば、より安全にLLMを活用できます。
7.3 社会への影響
LLMは、僕たちの社会に大きな変化をもたらす可能性を秘めています。
-** 教育の個別最適化 生徒一人ひとりの特性、学習進度、理解度に合わせて、最適な学習教材・学習方法を提供できるようになります。 - 医療の進化 AIによる画像診断の精度向上や、新薬開発のスピードアップなど、医療分野の進歩に大きく貢献することが期待されています。 - 雇用への影響 **一部の仕事はLLMに代替される可能性もありますが、一方で、LLMを活用した新しい仕事が生まれる可能性もあります。人間はよりクリエイティブなことに時間を費やすことになると思います。
LLMと共に生きる未来に向けて
今回は、LLMについて、基礎から応用、そして未来展望まで、幅広く解説してきました。
LLMは、僕たちの生活を大きく変える可能性を秘めた、非常にSF色の強い技術です。
しかし、その一方で、倫理的な課題や社会への影響など、解決すべき問題も山積しています。
大切なのは、LLMを正しく理解し、その可能性と課題を踏まえた上で、どのように活用していくかを、僕たち人間がしっかりと考えていくことです。
株式会社Elcamyでは、LLMをはじめとするAI技術の開発・導入支援を行っております。
AI技術にご興味をお持ちの方、導入を検討されている方は、ぜひお気軽にお問い合わせください。