こんにちは。株式会社Elcamyのデータサイエンティスト・AIエンジニアの近江俊樹です。
今日は、ウェブサイトから情報を自動取得するスクレイピングとそれらを用いた時の違法パターンについて解説します。
💡 ElcamyではGoogle Cloudを用いたデータ分析基盤の構築や、生成AIを用いた業務支援まで対応可能です。生成AIやデータ活用によって事業を前に進めたい方は、お気軽にご相談ください。
データ収集するときはスクレイピングの他にもほぼ必ずクローリングがセットになりますが、今回は「データ収集≒スクレイピング」でまとめてしまい、解説します。
クローリングの解説は本記事の主題ではないため、詳細の説明は別記事に譲りますが、以下に簡単な違いと説明を表にしておきます。
| **クローリング | スクレイピング** | |
|---|---|---|
| 目的 | Webサイトの探索 | 特定情報の抽出 |
| 対象 | Webサイト全体 | 特定のWebページや要素 |
| 機能 | リンクの追跡、サイトマップの読み込み | HTML解析、情報の抽出・加工 |
| 例 | 検索エンジンのインデックス作成 | 商品価格比較サイトのデータ収集 |
スクレイピングは、データ分析や市場調査など、ビジネスの様々な場面で役立つ強力なツールですが、その一方で、法的なリスクや倫理的な問題点も孕んでいます。
僕自身、AI開発のため、日々スクレイピング技術に触れる中で、その可能性と課題を強く感じています。
今回は、スクレイピングの基本的な仕組みから、具体的な事例、そして安全な実践方法まで、分かりやすく解説していきます。
💡 法律に関わる内容が含まれています。あくまで簡易的な説明になりますので、本記事情報の利用に関わる事象は自己責任となります。
1. スクレイピングとは?その仕組みと活用例
1.1 スクレイピングの定義:ウェブサイトから情報を自動収集
スクレイピングとは、ウェブサイトから構造化されていないデータを自動的に収集し、分析可能な形式に変換する技術のことです。
ウェブサイトは、人間がブラウザで見て理解しやすいように設計されていますが、その背後には以下のHTMLやCSSといったコードで書かれた構造が存在します。
人間の身体で例えると
HTML(以下例)は骨や骨格のようなもので

CSS(以下例)は皮膚の色や目の色などです。
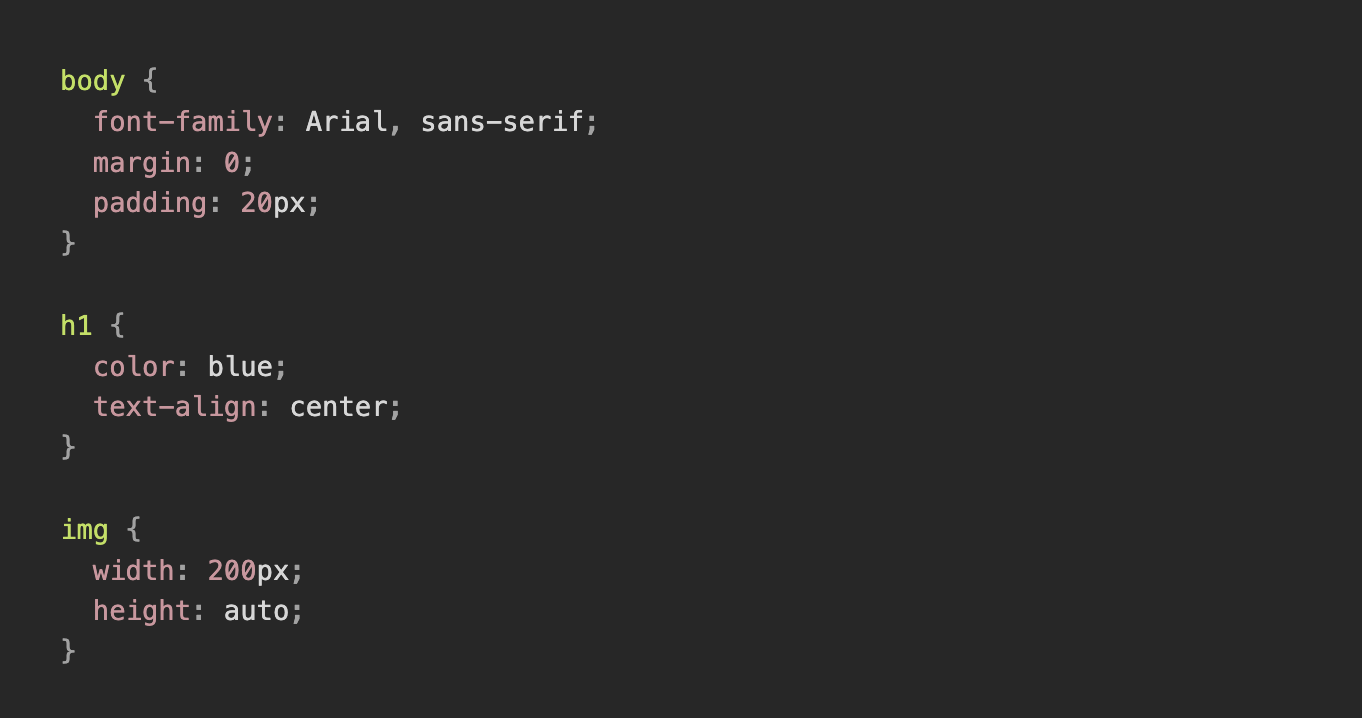
スクレイピングでは、この構造を解析することで、人間が目視で確認するよりもはるかに高速かつ大量に情報を収集することが可能になります。
1.2 スクレイピングの一般的な用途とメリット:価格比較、市場調査、データ分析…
スクレイピングは、その特性から、多岐にわたる分野で活用されています。いくつか例を挙げると、
- **価格比較サイト 複数のECサイトから商品価格や在庫情報を自動収集し、ユーザーに最適な商品を提示する。 - 市場調査 競合他社のウェブサイトから商品情報、価格推移、顧客レビューなどを収集し、市場動向を分析する。 - データ分析 ニュースサイトやブログなどから大量のテキストデータを収集し、自然言語処理を用いてトレンド分析や感情分析を行う。 - 求人情報収集 **求人サイトから企業情報、募集要項、給与などを収集し、転職希望者向けに最適な求人情報を提供する。
このように、スクレイピングは、従来は時間と手間のかかっていたデータ収集作業を自動化し、効率化を図る強力なツールとして、ビジネスに大きく貢献しています。
1.3 スクレイピングの技術的な概要:リクエスト送信からデータ保存まで
スクレイピングは、一般的に以下の手順で行われます。
| 手順 | 説明 | 使用ツール例 |
|---|---|---|
| 1. リクエストの送信 | スクレイピングしたいウェブサイトのURLに対して、HTTPリクエストを送信し、HTMLデータを取得する。 | Pythonのrequestsライブラリ |
| 2. HTMLの解析 | 取得したHTMLデータを解析し、必要な情報が含まれている要素を特定する。 | PythonのBeautiful Soupやlxmlライブラリ |
| 3. データの抽出 | 特定した要素から、テキスト、リンク、画像などのデータを抽出する。 | |
| 4. データの保存 | 抽出したデータをCSV、JSON、データベースなどに保存し、後の分析や利用に備える。 | Pythonのpandasライブラリ、データベース接続ライブラリ |
一見するとシンプルな手順ですが、効率的かつ正確なデータ収集を行うためには、ウェブサイトの構造を理解し、適切なツールやライブラリを選択する必要があります。
2. スクレイピングを行う際の注意点:法的リスク、倫理、技術…
2.1 サイトの利用規約を確認:スクレイピングを禁止している場合も
スクレイピングは、その性質上、ウェブサイトに負荷をかけたり、プライバシーを侵害する可能性を孕んでいます。そのため、多くのウェブサイトでは、利用規約 (Terms of Service) において、スクレイピングに関するルールを定めています。
例えば、
- **スクレイピングの全面禁止 ウェブサイト上のいかなるデータの自動収集も禁止する。 - 許可が必要なスクレイピング スクレイピングを行う場合は、事前にサイト運営者への連絡と許可が必要となる。 - アクセス頻度の制限 **短時間に大量のリクエストを送信することを禁止し、サーバーへの負荷を軽減する。
スクレイピングを行う前に、必ず対象となるウェブサイトの利用規約を確認し、ルールに従うようにしましょう。違反した場合、法的措置を取られたり、サイトへのアクセスをブロックされる可能性があります。
2.2 反復リクエストによるサーバー負荷の回避:アクセス頻度、時間帯…
スクレイピングでは、短時間に大量のアクセスをウェブサイトに送り続けるため、サーバーに大きな負荷をかける可能性があります。
これは、ウェブサイトのパフォーマンス低下や、最悪の場合、サービス停止に繋がる可能性もあるため、注意が必要です。
サーバー負荷を軽減するためには、以下の対策が有効です。
-** リクエストの間隔を設ける リクエストを送信する間隔を、数秒から数十秒程度空けることで、サーバーへの負担を軽減できます。 - アクセス時間帯を分散させる アクセスが集中する時間帯を避け、夜間や早朝など、サーバーへの負荷が低い時間帯にスクレイピングを行うようにしましょう。 - クローリングの速度を調整する **スクレイピングツールによっては、クローリングの速度を調整する機能が備わっています。サーバーへの負荷を見ながら、適切な速度に設定しましょう。
2.3 個人情報の取り扱い:取得、利用、保存…
スクレイピングによって取得したデータに、氏名、住所、電話番号、メールアドレスなどの個人情報が含まれる場合は、個人情報保護法などの関連法規に則って、適切に管理する必要があります。
具体的には、
-** 利用目的の特定 個人情報を取得する際は、その利用目的を明確化し、目的外の利用は行わないようにしましょう。 - 安全な保管 取得した個人情報は、漏洩、滅失、毀損などが発生しないよう、適切なセキュリティ対策を施した上で保管する必要があります。 - 第三者への提供 **個人情報を第三者に提供する場合は、本人の同意を得るなど、法令で定められた手続きを遵守する必要があります。
個人情報の取り扱いに関するルールは、国や地域によって異なるため、注意が必要です。
2.4 ボットの検出と対策:CAPTCHA、IPアドレスブロック…
多くのウェブサイトでは、スクレイピングなどの自動アクセスを検知し、ブロックする仕組みを導入しています。
代表的なものとしては、
-** CAPTCHA 人間とボットを判別するために用いられる、歪んだ文字や画像を選択させる認証システム。 - IPアドレスブロック 特定のIPアドレスからのアクセスを遮断する。 - ユーザーエージェントチェック **ウェブブラウザの種類やバージョンなどを識別する情報であるユーザーエージェントをチェックし、ボットと疑われるアクセスをブロックする。
これらの対策を回避するために、スクレイピングツールでは、
-** CAPTCHAの自動解答 機械学習を用いてCAPTCHAを自動で解答する機能。 - プロキシサーバーの利用 複数のプロキシサーバーを経由することで、アクセス元のIPアドレスを分散させる(IPローテーション)。 - ユーザーエージェントの偽装 **人間が利用するブラウザのユーザーエージェントを偽装することで、ボットと認識されにくくする。
といった機能が提供されている場合があります。
しかし、これらの機能を悪用すると、ウェブサイト運営者に迷惑をかけるだけでなく、法的な問題に発展する可能性もあるため、注意が必要です。
2.5 公開データと非公開データの区別:ログインが必要なページは要注意
スクレイピングを行う際には、対象となるデータが公開情報なのか、非公開情報なのかを明確に区別する必要があります。
- 公開情報:誰でも自由に閲覧できる情報。
- 非公開情報:特定の条件を満たしたユーザーのみが閲覧できる情報。
一般的に、公開情報のスクレイピングは、違法とはみなされにくい傾向にあります。
しかし、会員登録が必要なページや、ログインしないと閲覧できないページの情報をスクレイピングする場合は、注意が必要です。
これらのページに掲載されている情報は、非公開情報とみなされる可能性が高く、スクレイピングを行うことで、ウェブサイト運営者との間でトラブルになる可能性があります。
3. スクレイピングに関連する訴訟事例
スクレイピングの法的リスクを理解するために、実際に起こった訴訟事例を見ていきましょう。
3.1 有名な訴訟ケースの紹介:LinkedIn vs HiQ Labs、Ryanair vs Skyscanner…
| 訴訟事例 | 概要 | ポイント |
|---|---|---|
| LinkedIn vs HiQ Labs | データ分析会社HiQ Labsが、LinkedInの公開プロフィール情報をスクレイピングしてサービスを提供していたところ、LinkedIn側から利用規約違反を理由に提訴された。 | 公開情報のスクレイピングであっても、利用規約に違反する場合、違法となる可能性がある。 |
| Ryanair vs Skyscanner | 格安航空券比較サイトSkyscannerが、航空会社Ryanairのウェブサイトからフライト情報をスクレイピングして自社サービスに利用していたところ、Ryanair側から著作権侵害を理由に提訴された。 | 独自に作成されたデータベースや著作権で保護されているコンテンツを無断でスクレイピングすると、違法となる可能性がある。 |
違法事例について詳しい記事はこちら(【違法事例を3つ紹介】スクレイピングするときの注意事項)
3.2 判例から学ぶポイント:公開情報でも利用規約違反はアウト
これらの訴訟事例から、以下の点が分かります。
- 公開情報のスクレイピングであっても、ウェブサイトの利用規約に違反する場合、違法となる可能性がある。
- データベース権や著作権で保護されているコンテンツを無断でスクレイピングすると、違法となる可能性が高い。
スクレイピングを行う際には、常に最新の判例や法的動向を踏まえ、慎重に判断する必要があります。
4. スクレイピングの違法パターン
以下に、違法パターン別に具体例と法的リスクをまとめました。
| 違法パターン | 具体例 | 法的リスク |
|---|---|---|
| 利用規約違反 | ニュースサイトAは、利用規約において、記事コンテンツの自動収集を禁止している。企業Bが、ニュースサイトAの記事を無断でスクレイピングし、自社サイトに転載した。 | ・著作権侵害 ・不正競争防止法違反 |
| 著作権侵害 | 小説家Cの公式ウェブサイトから、掲載されている小説の全文を無断でスクレイピングし、別のウェブサイトで公開した。 | ・著作権法違反 |
| コンピュータ不正アクセス法違反 | 企業Dは、競合他社Eのウェブサイトから、顧客情報を不正に取得するために、スクレイピングツールを使って、パスワードが設定されていない管理画面にアクセスしようとした。 | ・コンピュータ不正アクセス法違反 |
| データベース権侵害 | 企業Fは、オンラインショッピングサイトGが独自に構築した商品データベースを、スクレイピングツールを使って無断で複製し、自社のサービスで利用した。 | ・データベース権侵害 ・不正競争防止法違反 |
5. 合法的なスクレイピングの方法
5.1 APIの利用:公式に提供されたデータ取得手段
API (Application Programming Interface) とは、ウェブサイトが外部のアプリケーションに対して、データや機能へのアクセスを提供するためのインターフェースです。
例えば、あるSNSの公式のAPI(例:X API)を利用すると、投稿の検索・取得・投稿などの操作をプログラムから自動的に行うことができます。APIを利用する利点としては以下が挙げられます。
-** 安定したデータ取得 APIは、スクレイピングと比較して、ウェブサイトの構造変化の影響を受けにくく、安定したデータ取得が可能です。 - 利用規約の遵守 **APIを利用したデータ取得は、ウェブサイト運営者が公式に認めている方法であるため、利用規約違反となるリスクが低いです。
APIの利用には料金がかかるものが多いのですが、多くはエンジニアでないとわかりかねるような記載になっており、かつ複雑な場合が多いです。
エンジニアにざっくりと説明してほしいと思うかもしれませんが、ざっくり説明すると認識違いが生まれトラブルに繋がるので、ざっくりとした説明をしたくないという場合が多いです。
以下はX APIの料金表ですが、かなりシンプルな方です。
料金を見て、何をするかという進め方だと検討事項が無数に発生してしまうので
何をしたいかを仮決めして、プランを選び、予算内に収まらないときは妥協事項をプラン表を見ながら決めていくという進め方が良いと思います。
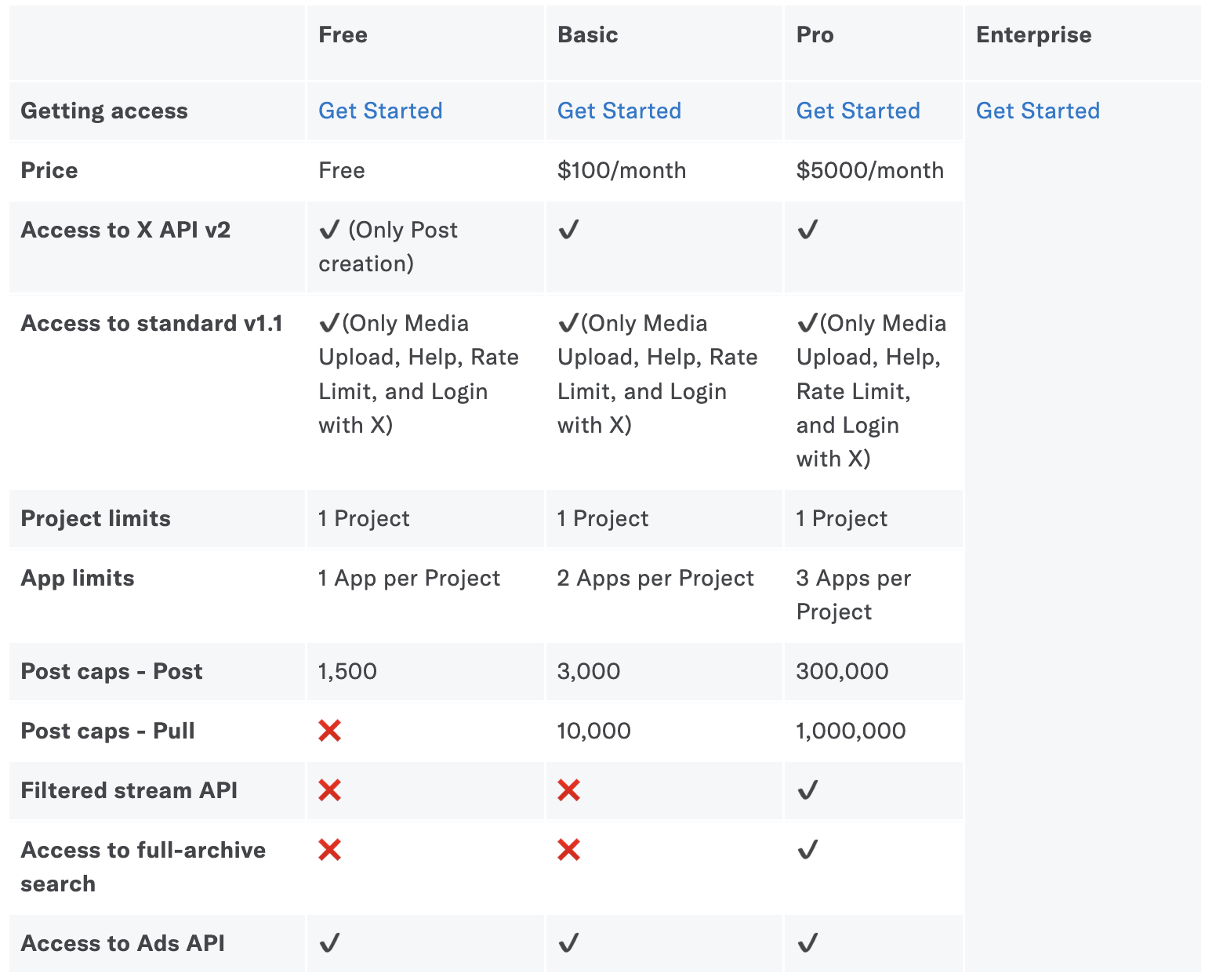
(引用:公式X APIページ)
5.2 ロボット排除標準 (robots.txt) の遵守:アクセス許可を確認
robots.txtとは、ウェブサイトのルートディレクトリに配置されるファイルで、クローラー(検索エンジンのボットなど)に対して、ウェブサイト内のどのページへのアクセスを許可するかを指示するためのものです。
具体例
User-agent: *
Disallow: /private/
User-agent: Googlebot
Disallow: /
- 上記の例では、
/private/ディレクトリへのアクセスは、全てのクローラーに対して禁止されています。 - また、Googlebotに対しては、ウェブサイト全体へのアクセスを禁止しています。
- robots.txtに従うことで、ウェブサイト運営者の意向を尊重し、トラブルを避けることができます。
- 公園の注意書きに「花火をしてはいけません」と書いてあるようなもので、スクレイピング自体はできてしまうこともあるかもしれませんが、ウェブサイトの運営者がいるおかげでデータを見れているかつトラブルになるので、絶対に守りましょう。(当然ですが、利用規約にも言えます)
5.3 法的アドバイスの取得:専門家の意見を参考に
とはいえ、例えば、利用規約の書き方が非常に曖昧で、どのようにも解釈できてしまうような場合もあると思います。スクレイピングを行う際には、事前に弁護士などの専門家に相談し、法的リスクを評価してもらうことをおすすめします。
- スクレイピング対象のウェブサイトの利用規約の解釈
- スクレイピングによって取得したデータの利用方法
- 競合他社の情報収集における注意点
5.4 スクレイピングツールの選択と設定:適切なツールでリスク軽減
💡 以下の方法はエンジニア向けですが、弊社テックブログにて非エンジニアでもスクレイピングできる方法をご紹介しています→【Firecrawlの使い方】非エンジニアでもできるクローリング・スクレイピングツール
スクレイピングを行う際には、目的や規模に応じて、適切なツールを選択する必要があります。
-** Pythonの****requestsライブラリ、Beautiful Soupライブラリ:
比較的シンプルなスクレイピングに適しています。
- Pythonの****Scrapy****フレームワーク
**大規模なスクレイピングや、複雑なウェブサイトからのデータ取得に適しています。
ツールを選択するだけでなく、適切な設定を行うことも重要です。
-** リクエストの間隔 ウェブサイトに負荷をかけすぎないように、リクエストの間隔を適切に設定しましょう。 - ユーザーエージェント **スクレイピングツールだと認識されないようにしましょう。ただし、ユーザーエージェントを使って、不正なアクセスを行ってはいけません。
- IPローテンション 複数のIPを用いてスクレイピングツールだと認識されないようにしましょう。ただし、不正なアクセスを行ってはいけません。
6. スクレイピングは、正しく使えばデータの未来を変える手段
スクレイピングは、使い方次第で、違法行為とみなされる可能性があります。
これはスクレイピングに限らず、包丁やハンマーといった道具にも言えます。
使い方一つで、違法にも合法にもなってしまいます。
道具を使うのは人であり、人の行いが善悪を決めます。罪を犯すのは道具ではありません。
上記を常に意識しつつ、最新の法律や判例を参考に、合法的な範囲内でスクレイピングを行うように心がけましょう。
以上、ご紹介した基本的なリスクをまとめると以下になります。
| リスク | 対策 |
|---|---|
| 法的リスク | 利用規約の確認、APIの利用、法的アドバイスを受ける |
| 技術的リスク | サーバー負荷の軽減、ボット検知の回避 |
| 倫理的リスク | 個人情報、著作権 |
スクレイピングは、正しく使えば、ビジネスや研究に役立つ強力なツールです。
しかし、その一方で、法的なリスクや倫理的な問題点も存在することを忘れてはなりません。
スクレイピングを行う際には、常にリスクを意識し、適切な対策を講じるように心がけましょう。
またスクレイピングを専門としている会社が公開している記事も法的リスクについてわかりやすくまとまっておりますので、参考にしてみてください。
最後になりましたが、より効率的データ収集・より高度な分析・よりクリエイティブな意思決定をしていきましょう。
最後までお読みいただきありがとうございました。
株式会社Elcamyは、データ分析・AI開発のプロフェッショナル集団です。
データ分析、AI開発などお気軽にご相談ください。